Negative Implicit Feedback in Recommendations
A tutorial to demonstrate the process of training and evaluating various recommender models on a online retail store data. Along with the positive feedbacks like view, add-to-cart, we also have a negative event 'remove-from-cart'.
!pip install git+https://github.com/maciejkula/spotlight.git@master#egg=spotlight
!git clone https://github.com/microsoft/recommenders.git
!pip install cornac
!pip install pandas==0.25.0
import os
import sys
import math
import random
import datetime
import itertools
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn import preprocessing
from scipy.sparse import csr_matrix, dok_matrix
from sklearn.model_selection import ParameterGrid
from fastai.collab import *
from fastai.tabular import *
from fastai.text import *
import cornac
from spotlight.interactions import Interactions
from spotlight.interactions import SequenceInteractions
from spotlight.cross_validation import random_train_test_split
from spotlight.cross_validation import user_based_train_test_split
from spotlight.factorization.implicit import ImplicitFactorizationModel
from spotlight.evaluation import mrr_score
from spotlight.evaluation import precision_recall_score
from spotlight.interactions import Interactions
from spotlight.cross_validation import random_train_test_split
from spotlight.cross_validation import user_based_train_test_split
from spotlight.factorization.implicit import ImplicitFactorizationModel
from spotlight.evaluation import mrr_score
from spotlight.evaluation import precision_recall_score
from spotlight.interactions import SequenceInteractions
from spotlight.sequence.implicit import ImplicitSequenceModel
from spotlight.evaluation import sequence_mrr_score
from spotlight.evaluation import sequence_precision_recall_score
import warnings
warnings.filterwarnings("ignore")
sys.path.append('/content/recommenders/')
from reco_utils.dataset.python_splitters import python_chrono_split
from reco_utils.evaluation.python_evaluation import map_at_k
from reco_utils.evaluation.python_evaluation import precision_at_k
from reco_utils.evaluation.python_evaluation import ndcg_at_k
from reco_utils.evaluation.python_evaluation import recall_at_k
from reco_utils.evaluation.python_evaluation import get_top_k_items
from reco_utils.recommender.cornac.cornac_utils import predict_ranking
Data Loading
# loading data
df = pd.read_csv('rawdata.csv', header = 0,
names = ['event','userid','itemid','timestamp'],
dtype={0:'category', 1:'category', 2:'category'},
parse_dates=['timestamp'])
df.head()
df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 99998 entries, 0 to 99997
Data columns (total 4 columns):
event 99998 non-null category
userid 99998 non-null category
itemid 99998 non-null category
timestamp 99998 non-null datetime64[ns, UTC]
dtypes: category(3), datetime64[ns, UTC](1)
memory usage: 1.7 MB
Wrangling
Removing Duplicates
# dropping exact duplicates
df = df.drop_duplicates()
Label Encoding
# userid normalization
userid_encoder = preprocessing.LabelEncoder()
df.userid = userid_encoder.fit_transform(df.userid)
# itemid normalization
itemid_encoder = preprocessing.LabelEncoder()
df.itemid = itemid_encoder.fit_transform(df.itemid)
Exploration
df.describe().T
df.describe(exclude='int').T
df.timestamp.max() - df.timestamp.min()
Timedelta('56 days 20:56:50.132000')
df.event.value_counts()
begin_checkout 41459
view_item 35397
purchase 9969
add_to_cart 7745
remove_from_cart 4862
Name: event, dtype: int64
df.event.value_counts()/df.userid.nunique()
begin_checkout 3.612355
view_item 3.084168
purchase 0.868607
add_to_cart 0.674828
remove_from_cart 0.423630
Name: event, dtype: float64
User Interactions
# User events
user_activity_count = dict()
for row in df.itertuples():
if row.userid not in user_activity_count:
user_activity_count[row.userid] = {'view_item':0,
'add_to_cart':0,
'begin_checkout':0,
'remove_from_cart':0,
'purchase':0}
if row.event == 'view_item':
user_activity_count[row.userid]['view_item'] += 1
elif row.event == 'add_to_cart':
user_activity_count[row.userid]['add_to_cart'] += 1
elif row.event == 'begin_checkout':
user_activity_count[row.userid]['begin_checkout'] += 1
elif row.event == 'remove_from_cart':
user_activity_count[row.userid]['remove_from_cart'] += 1
elif row.event == 'purchase':
user_activity_count[row.userid]['purchase'] += 1
user_activity = pd.DataFrame(user_activity_count)
user_activity = user_activity.transpose()
user_activity['activity'] = user_activity.sum(axis=1)
tempDF = pd.DataFrame(user_activity.activity.value_counts()).reset_index()
tempDF.columns = ['#Interactions','#Users']
sns.scatterplot(x='#Interactions', y='#Users', data=tempDF);

df_activity = user_activity.copy()
event = df_activity.columns.astype('str')
sns.countplot(df_activity.loc[df_activity[event[0]]>0,event[0]]);
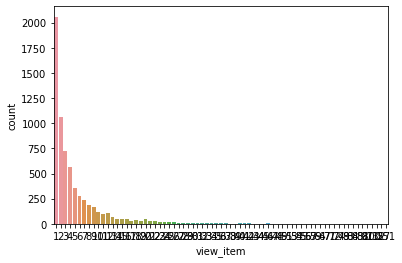
Add-to-cart Event Counts
sns.countplot(df_activity.loc[df_activity[event[1]]>0,event[1]])
plt.show()

Purchase Event Counts
sns.countplot(df_activity.loc[df_activity[event[4]]>0,event[4]])
plt.show()

Item Interactions
# item events
item_activity_count = dict()
for row in df.itertuples():
if row.itemid not in item_activity_count:
item_activity_count[row.itemid] = {'view_item':0,
'add_to_cart':0,
'begin_checkout':0,
'remove_from_cart':0,
'purchase':0}
if row.event == 'view_item':
item_activity_count[row.itemid]['view_item'] += 1
elif row.event == 'add_to_cart':
item_activity_count[row.itemid]['add_to_cart'] += 1
elif row.event == 'begin_checkout':
item_activity_count[row.itemid]['begin_checkout'] += 1
elif row.event == 'remove_from_cart':
item_activity_count[row.itemid]['remove_from_cart'] += 1
elif row.event == 'purchase':
item_activity_count[row.itemid]['purchase'] += 1
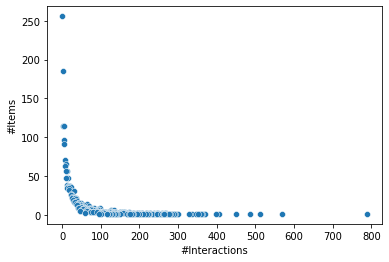
item_activity = pd.DataFrame(item_activity_count)
item_activity = item_activity.transpose()
item_activity['activity'] = item_activity.sum(axis=1)
tempDF = pd.DataFrame(item_activity.activity.value_counts()).reset_index()
tempDF.columns = ['#Interactions','#Items']
sns.scatterplot(x='#Interactions', y='#Items', data=tempDF);
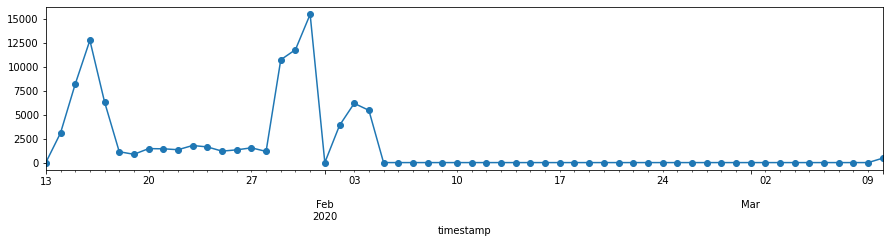
plt.rcParams['figure.figsize'] = 15,3
data = pd.DataFrame(pd.to_datetime(df['timestamp'], infer_datetime_format=True))
data['Count'] = 1
data.set_index('timestamp', inplace=True)
data = data.resample('D').apply({'Count':'count'})
ax = data['Count'].plot(marker='o', linestyle='-')
Rule-based Approaches
Top-N Trending Products
def top_trending(n, timeperiod, timestamp):
start = str(timestamp.replace(microsecond=0) - pd.Timedelta(minutes=timeperiod))
end = str(timestamp.replace(microsecond=0))
trending_items = df.loc[(df.timestamp.between(start,end) & (df.event=='view_item')),:].sort_values('timestamp', ascending=False)
return trending_items.itemid.value_counts().index[:n]
user_current_time = df.timestamp[100]
top_trending(5, 50, user_current_time)
Int64Index([2241, 972, 393, 1118, 126], dtype='int64')
Top-N Least Viewed Items
def least_n_items(n=10):
temp1 = df.loc[df.event=='view_item'].groupby(['itemid'])['event'].count().sort_values(ascending=True).reset_index()
temp2 = df.groupby('itemid').timestamp.max().reset_index()
item_ids = pd.merge(temp1,temp2,on='itemid').sort_values(['event', 'timestamp'], ascending=[True, False]).reset_index().loc[:n-1,'itemid']
return itemid_encoder.inverse_transform(item_ids.values)
least_n_items(10)
array(['15742', '16052', '16443', '16074', '16424', '11574', '11465', '16033', '11711', '16013'], dtype=object)
Data Transformation
Many times there are no explicit ratings or preferences given by users, that is, the interactions are usually implicit. This information may reflect users' preference towards the items in an implicit manner.
Option 1 - Simple Count: The most simple technique is to count times of interactions between user and item for producing affinity scores.
Option 2 - Weighted Count: It is useful to consider the types of different interactions as weights in the count aggregation. For example, assuming weights of the three differen types, "click", "add", and "purchase", are 1, 2, and 3, respectively.
Option 3 - Time-dependent Count: In many scenarios, time dependency plays a critical role in preparing dataset for building a collaborative filtering model that captures user interests drift over time. One of the common techniques for achieving time dependent count is to add a time decay factor in the counting.
A. Count
data_count = df.groupby(['userid', 'itemid']).agg({'timestamp': 'count'}).reset_index()
data_count.columns = ['userid', 'itemid', 'affinity']
data_count.head()
B. Weighted Count
data_w = df.loc[df.event!='remove_from_cart',:]
affinity_weights = {
'view_item': 1,
'add_to_cart': 3,
'begin_checkout': 5,
'purchase': 6,
'remove_from_cart': 3
}
data_w['event'].apply(lambda x: affinity_weights[x])
data_w.head()
data_w['weight'] = data_w['event'].apply(lambda x: affinity_weights[x])
data_wcount = data_w.groupby(['userid', 'itemid'])['weight'].sum().reset_index()
data_wcount.columns = ['userid', 'itemid', 'affinity']
data_wcount.head()
C. Time dependent Count
T = 30
t_ref = datetime.datetime.utcnow()
data_w['timedecay'] = data_w.apply(
lambda x: x['weight'] * math.exp(-math.log2((t_ref - pd.to_datetime(x['timestamp']).tz_convert(None)).days / T)),
axis=1
)
data_w.head()
data_wt = data_w.groupby(['userid', 'itemid'])['timedecay'].sum().reset_index()
data_wt.columns = ['userid', 'itemid', 'affinity']
data_wt.head()
Train Test Split
Option 1 - Random Split: Random split simply takes in a data set and outputs the splits of the data, given the split ratios
Option 2 - Chronological split: Chronogically splitting method takes in a dataset and splits it on timestamp
data = data_w[['userid','itemid','timedecay','timestamp']]
col = {
'col_user': 'userid',
'col_item': 'itemid',
'col_rating': 'timedecay',
'col_timestamp': 'timestamp',
}
col3 = {
'col_user': 'userid',
'col_item': 'itemid',
'col_timestamp': 'timestamp',
}
train, test = python_chrono_split(data, ratio=0.75, min_rating=10,
filter_by='user', **col3)
train.loc[train.userid==7,:]
Experiments
Item Popularity Recomendation Model
# Recommending the most popular items is intuitive and simple approach
item_counts = train['itemid'].value_counts().to_frame().reset_index()
item_counts.columns = ['itemid', 'count']
item_counts.head()
user_item_col = ['userid', 'itemid']
# Cross join users and items
test_users = test['userid'].unique()
user_item_list = list(itertools.product(test_users, item_counts['itemid']))
users_items = pd.DataFrame(user_item_list, columns=user_item_col)
print("Number of user-item pairs:", len(users_items))
# Remove seen items (items in the train set) as we will not recommend those again to the users
from reco_utils.dataset.pandas_df_utils import filter_by
users_items_remove_seen = filter_by(users_items, train, user_item_col)
print("After remove seen items:", len(users_items_remove_seen))
Number of user-item pairs: 4124250
After remove seen items: 4107466
# Generate recommendations
baseline_recommendations = pd.merge(item_counts, users_items_remove_seen,
on=['itemid'], how='inner')
baseline_recommendations.head()
k = 10
cols = {
'col_user': 'userid',
'col_item': 'itemid',
'col_rating': 'timedecay',
'col_prediction': 'count',
}
eval_map = map_at_k(test, baseline_recommendations, k=k, **cols)
eval_ndcg = ndcg_at_k(test, baseline_recommendations, k=k, **cols)
eval_precision = precision_at_k(test, baseline_recommendations, k=k, **cols)
eval_recall = recall_at_k(test, baseline_recommendations, k=k, **cols)
print("MAP:\t%f" % eval_map,
"NDCG@K:\t%f" % eval_ndcg,
"Precision@K:\t%f" % eval_precision,
"Recall@K:\t%f" % eval_recall, sep='\n')
MAP: 0.005334
NDCG@K: 0.010356
Precision@K: 0.007092
Recall@K: 0.011395
Cornac BPR Model
TOP_K = 10
NUM_FACTORS = 200
NUM_EPOCHS = 100
SEED = 40
train_set = cornac.data.Dataset.from_uir(train.itertuples(index=False), seed=SEED)
bpr = cornac.models.BPR(
k=NUM_FACTORS,
max_iter=NUM_EPOCHS,
learning_rate=0.01,
lambda_reg=0.001,
verbose=True,
seed=SEED
)
from reco_utils.common.timer import Timer
with Timer() as t:
bpr.fit(train_set)
print("Took {} seconds for training.".format(t))
HBox(children=(FloatProgress(value=0.0), HTML(value='')))
Optimization finished!
Took 3.1812 seconds for training.
with Timer() as t:
all_predictions = predict_ranking(bpr, train, usercol='userid', itemcol='itemid', remove_seen=True)
print("Took {} seconds for prediction.".format(t))
Took 4.7581 seconds for prediction.
all_predictions.head()
k = 10
cols = {
'col_user': 'userid',
'col_item': 'itemid',
'col_rating': 'timedecay',
'col_prediction': 'prediction',
}
eval_map = map_at_k(test, all_predictions, k=k, **cols)
eval_ndcg = ndcg_at_k(test, all_predictions, k=k, **cols)
eval_precision = precision_at_k(test, all_predictions, k=k, **cols)
eval_recall = recall_at_k(test, all_predictions, k=k, **cols)
print("MAP:\t%f" % eval_map,
"NDCG:\t%f" % eval_ndcg,
"Precision@K:\t%f" % eval_precision,
"Recall@K:\t%f" % eval_recall, sep='\n')
MAP: 0.004738
NDCG: 0.009597
Precision@K: 0.006601
Recall@K: 0.010597
SARS Model
from reco_utils.recommender.sar.sar_singlenode import SARSingleNode
TOP_K = 10
header = {
"col_user": "userid",
"col_item": "itemid",
"col_rating": "timedecay",
"col_timestamp": "timestamp",
"col_prediction": "prediction",
}
model = SARSingleNode(
similarity_type="jaccard",
time_decay_coefficient=0,
time_now=None,
timedecay_formula=False,
**header
)
model.fit(train)
top_k = model.recommend_k_items(test, remove_seen=True)
# all ranking metrics have the same arguments
args = [test, top_k]
kwargs = dict(col_user='userid',
col_item='itemid',
col_rating='timedecay',
col_prediction='prediction',
relevancy_method='top_k',
k=TOP_K)
eval_map = map_at_k(*args, **kwargs)
eval_ndcg = ndcg_at_k(*args, **kwargs)
eval_precision = precision_at_k(*args, **kwargs)
eval_recall = recall_at_k(*args, **kwargs)
print(f"Model:",
f"Top K:\t\t {TOP_K}",
f"MAP:\t\t {eval_map:f}",
f"NDCG:\t\t {eval_ndcg:f}",
f"Precision@K:\t {eval_precision:f}",
f"Recall@K:\t {eval_recall:f}", sep='\n')
Model:
Top K: 10
MAP: 0.024426
NDCG: 0.032738
Precision@K: 0.019258
Recall@K: 0.036009
Spotlight
Implicit Factorization Model
interactions = Interactions(user_ids = df.userid.astype('int32').values,
item_ids = df.itemid.astype('int32').values,
timestamps = df.timestamp.astype('int32'),
num_users = df.userid.nunique(),
num_items = df.itemid.nunique())
train_user, test_user = random_train_test_split(interactions, test_percentage=0.2)
model = ImplicitFactorizationModel(loss='bpr', embedding_dim=64, n_iter=10,
batch_size=256, l2=0.0, learning_rate=0.01,
optimizer_func=None, use_cuda=False,
representation=None, sparse=False,
num_negative_samples=10)
model.fit(train_user, verbose=1)
pr = precision_recall_score(model, test=test_user, train=train_user, k=10)
print('Pricison@10 is {:.3f} and Recall@10 is {:.3f}'.format(pr[0].mean(), pr[1].mean()))
Epoch 0: loss 0.26659833122392174
Epoch 1: loss 0.06129162273462562
Epoch 2: loss 0.022607273167640066
Epoch 3: loss 0.013953083943443858
Epoch 4: loss 0.01050195922488137
Epoch 5: loss 0.009170394043447121
Epoch 6: loss 0.008144461540834697
Epoch 7: loss 0.007209992620171649
Epoch 8: loss 0.00663076309035038
Epoch 9: loss 0.006706491189820159
Pricison@10 is 0.007 and Recall@10 is 0.050
Implicit Factorization Model with Grid Search
interactions = Interactions(user_ids = df.userid.astype('int32').values,
item_ids = df.itemid.astype('int32').values,
timestamps = df.timestamp.astype('int32'),
num_users = df.userid.nunique(),
num_items = df.itemid.nunique())
train_user, test_user = random_train_test_split(interactions, test_percentage=0.2)
params_grid = {'loss':['bpr', 'hinge'],
'embedding_dim':[32, 64],
'learning_rate': [0.01, 0.05, 0.1],
'num_negative_samples': [5,10,50]
}
grid = ParameterGrid(params_grid)
for p in grid:
model = ImplicitFactorizationModel(**p, n_iter=10, batch_size=256, l2=0.0,
optimizer_func=None, use_cuda=False,
representation=None, sparse=False)
model.fit(train_user, verbose=1)
pr = precision_recall_score(model, test=test_user, train=train_user, k=10)
print('Pricison@10 is {:.3f} and Recall@10 is {:.3f}'.format(pr[0].mean(), pr[1].mean()))
/usr/local/lib/python3.7/dist-packages/pandas/core/series.py:1139: FutureWarning:
Passing list-likes to .loc or [] with any missing label will raise
KeyError in the future, you can use .reindex() as an alternative.
See the documentation here:
https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#deprecate-loc-reindex-listlike
return self.loc[key]
Epoch 0: loss 0.23323329780071111
Epoch 1: loss 0.13417892158031464
Epoch 2: loss 0.11723061798326072
Epoch 3: loss 0.10971038677157696
Epoch 4: loss 0.1073669156125504
Epoch 5: loss 0.10198603978925579
Epoch 6: loss 0.10140255498445302
Epoch 7: loss 0.09986353406856298
Epoch 8: loss 0.09296791315366218
Epoch 9: loss 0.09289196610354918
Pricison@10 is 0.004 and Recall@10 is 0.026
Epoch 0: loss 1.8212750715074815
Epoch 1: loss 2.368166323068441
Epoch 2: loss 2.2547610501767736
Epoch 3: loss 2.0896969359978987
Epoch 4: loss 2.074246685221264
Epoch 5: loss 2.107905259206172
Epoch 6: loss 2.1261368730252195
Epoch 7: loss 2.0352458648168006
Epoch 8: loss 2.1936914333384903
Epoch 9: loss 2.0269214924412906
Pricison@10 is 0.004 and Recall@10 is 0.031
Epoch 0: loss 1.8324132722673692
Epoch 1: loss 2.4329963008307183
Epoch 2: loss 2.2162452385164917
Epoch 3: loss 2.092274981104676
Epoch 4: loss 2.1043862517432
Epoch 5: loss 2.0506169550671838
Epoch 6: loss 2.1609063529412462
Epoch 7: loss 2.1431561312683143
Epoch 8: loss 2.0215363380322504
Epoch 9: loss 1.9930379555180333
Pricison@10 is 0.004 and Recall@10 is 0.028
Epoch 0: loss 1.8448880979869144
Epoch 1: loss 2.378598579448136
Epoch 2: loss 2.296310121415129
Epoch 3: loss 2.131826051657606
Epoch 4: loss 2.101037339573888
Epoch 5: loss 2.0981224655530077
Epoch 6: loss 2.1441538588793714
Epoch 7: loss 2.014261698416192
Epoch 8: loss 1.9355182779228188
Epoch 9: loss 2.084795298492027
Pricison@10 is 0.004 and Recall@10 is 0.030
CNN Pooling Sequence Model
interactions = Interactions(user_ids = df.userid.astype('int32').values,
item_ids = df.itemid.astype('int32').values+1,
timestamps = df.timestamp.astype('int32'))
train, test = random_train_test_split(interactions, test_percentage=0.2)
train_seq = train.to_sequence(max_sequence_length=10)
test_seq = test.to_sequence(max_sequence_length=10)
model = ImplicitSequenceModel(loss='bpr', representation='pooling',
embedding_dim=32, n_iter=10, batch_size=256,
l2=0.0, learning_rate=0.01, optimizer_func=None,
use_cuda=False, sparse=False, num_negative_samples=5)
model.fit(train_seq, verbose=1)
mrr_seq = sequence_mrr_score(model, test_seq)
mrr_seq.mean()
Epoch 0: loss 0.4226887328702895
Epoch 1: loss 0.23515070266410953
Epoch 2: loss 0.16919970976524665
Epoch 3: loss 0.1425025990751923
Epoch 4: loss 0.12612225017586692
Epoch 5: loss 0.11565039795441706
Epoch 6: loss 0.10787886735357222
Epoch 7: loss 0.10086931410383006
Epoch 8: loss 0.09461003749585542
Epoch 9: loss 0.09128284808553633
0.10435609591957387
FastAI CollabLearner
df['rating'] = df['event'].map({'view_item': 1,
'add_to_cart': 2,
'begin_checkout': 3,
'purchase': 5,
'remove_from_cart': 0,
})
ratings = df[["userid", 'itemid', "rating", 'timestamp']].copy()
data = CollabDataBunch.from_df(ratings, seed=42)
data
TabularDataBunch;
Train: LabelList (79546 items)
x: CollabList
userid 3141; itemid 236; ,userid 3421; itemid 1001; ,userid 550; itemid 972; ,userid 550; itemid 972; ,userid 550; itemid 972;
y: FloatList
1.0,2.0,1.0,1.0,2.0
Path: .;
Valid: LabelList (19886 items)
x: CollabList
userid 6785; itemid 183; ,userid 1458; itemid 1356; ,userid 3817; itemid 2368; ,userid 9777; itemid 2466; ,userid 11077; itemid 1359;
y: FloatList
1.0,3.0,3.0,1.0,2.0
Path: .;
Test: None
learn = collab_learner(data, n_factors=50, y_range=[0,5.5])
learn.lr_find()
learn.recorder.plot(skip_end=15)
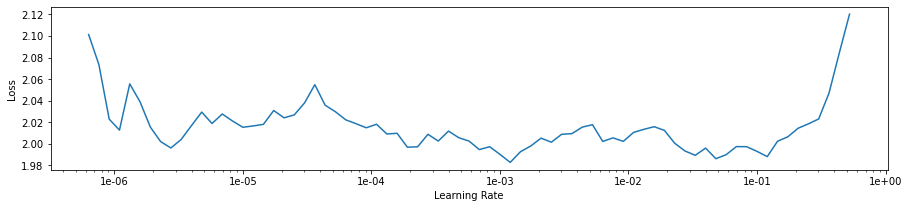
learn.fit_one_cycle(1, 5e-6)
learn.summary()
EmbeddingDotBias
======================================================================
Layer (type) Output Shape Param # Trainable
======================================================================
Embedding [50] 534,000 True
______________________________________________________________________
Embedding [50] 129,150 True
______________________________________________________________________
Embedding [1] 10,680 True
______________________________________________________________________
Embedding [1] 2,583 True
______________________________________________________________________
Total params: 676,413
Total trainable params: 676,413
Total non-trainable params: 0
Optimized with 'torch.optim.adam.Adam', betas=(0.9, 0.99)
Using true weight decay as discussed in https://www.fast.ai/2018/07/02/adam-weight-decay/
Loss function : FlattenedLoss
======================================================================
Callbacks functions applied
learn.fit(10, 1e-3)