Text Embeddings
Utilities
Averaging word vectors to create sentence vector
In case we already have the vectors for the words in the text, it makes sense to aggregate the word embeddings into a single vector representing the whole text.
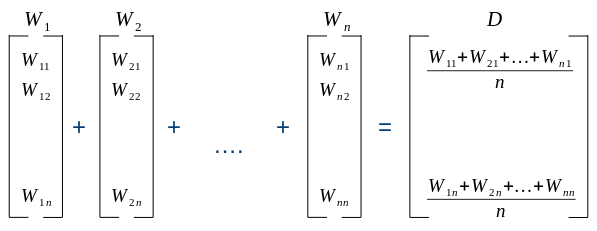
This is a great baseline approach chosen by many practitioners, and probably the one we should take first if we already have the word vectors or can easily obtain them.
The most frequent operations for aggregation are:
- averaging
- max-pooling
def get_mean_vector(words, word2vec_model):
# remove out-of-vocabulary words
words = [word for word in words if word in word2vec_model.wv.vocab]
if len(words) >= 1:
return np.mean(word2vec_model.wv[words], axis=0)
else:
return []
Word2vec
Training a custom Word2vec CBoW model with Gensim
model_cbow = gensim.models.Word2Vec(window=10, min_count=10, workers=2, size=100)
model_cbow.build_vocab(df.tokens.tolist())
model_cbow.train(df.tokens.tolist(), total_examples=model_cbow.corpus_count, epochs=20)
df['vecs_w2v_cbow'] = df['tokens'].apply(get_mean_vector, word2vec_model=model_cbow)
df.head()
Training a custom Word2vec SkipGram model with Gensim
model_sg = gensim.models.Word2Vec(window=10, min_count=10, workers=2, size=100, sg=1)
model_sg.build_vocab(df.tokens.tolist())
model_sg.train(df.tokens.tolist(), total_examples=model_sg.corpus_count, epochs=20)
df['vecs_w2v_sg'] = df['tokens'].apply(get_mean_vector, word2vec_model=model_sg)
df.head()
GloVe
Files with the pre-trained vectors Glove can be found in many sites like Kaggle or in the previous link of the Stanford University. We will use the glove.6B.100d.txt file containing the glove vectors trained on the Wikipedia and GigaWord dataset.
First we convert the GloVe file containing the word embeddings to the word2vec format for convenience of use. We can do it using the gensim library, a function called glove2word2vec.
wget -O glove.6B.zip -q --show-progress https://nlp.stanford.edu/data/glove.6B.zip
unzip glove.6B.zip
# We just need to run this code once, the function glove2word2vec saves the Glove embeddings in the word2vec format
# that will be loaded in the next section
from gensim.scripts.glove2word2vec import glove2word2vec
# glove_input_file = glove_filename
word2vec_output_file = 'glove.word2vec'
glove2word2vec('glove.6B.100d.txt', word2vec_output_file)
So our vocabulary contains 400K words represented by a feature vector of shape 100. Now we can load the Glove embeddings in word2vec format and then analyze some analogies. In this way if we want to use a pre-trained word2vec embeddings we can simply change the filename and reuse all the code below.
# load the Stanford GloVe model
model_glove = KeyedVectors.load_word2vec_format(word2vec_output_file, binary=False)
df['vecs_w2v_glove'] = df['tokens'].apply(get_mean_vector, word2vec_model=model_glove)
df.head()
TF-IDF
The TfidfVectorizer will tokenize documents, learn the vocabulary and inverse document frequency weightings, and allow you to encode new documents. Alternately, if you already have a learned CountVectorizer, you can use it with a TfidfTransformer to just calculate the inverse document frequencies and start encoding documents.
Counts and frequencies can be very useful, but one limitation of these methods is that the vocabulary can become very large.
This, in turn, will require large vectors for encoding documents and impose large requirements on memory and slow down algorithms.
A clever work around is to use a one way hash of words to convert them to integers. The clever part is that no vocabulary is required and you can choose an arbitrary-long fixed length vector. A downside is that the hash is a one-way function so there is no way to convert the encoding back to a word (which may not matter for many supervised learning tasks).
The HashingVectorizer class implements this approach that can be used to consistently hash words, then tokenize and encode documents as needed.
from sklearn.feature_extraction.text import HashingVectorizer
# create the transform
vectorizer = HashingVectorizer(n_features=100)
# encode document
vector = vectorizer.transform(df.clean_text.tolist())
# summarize encoded vector
print(vector.shape)
df['vecs_tfidf'] = list(vector.toarray())
df.head()
BERT
Sentence BERT
from sentence_transformers import SentenceTransformer
sbert_model = SentenceTransformer('bert-base-nli-mean-tokens')
df['vecs_bert'] = df['clean_text'].progress_apply(sbert_model.encode)