Amazon Personalize
caution
This page is a random dump of my notes on Amazon Personalize. Proceed accordingly.
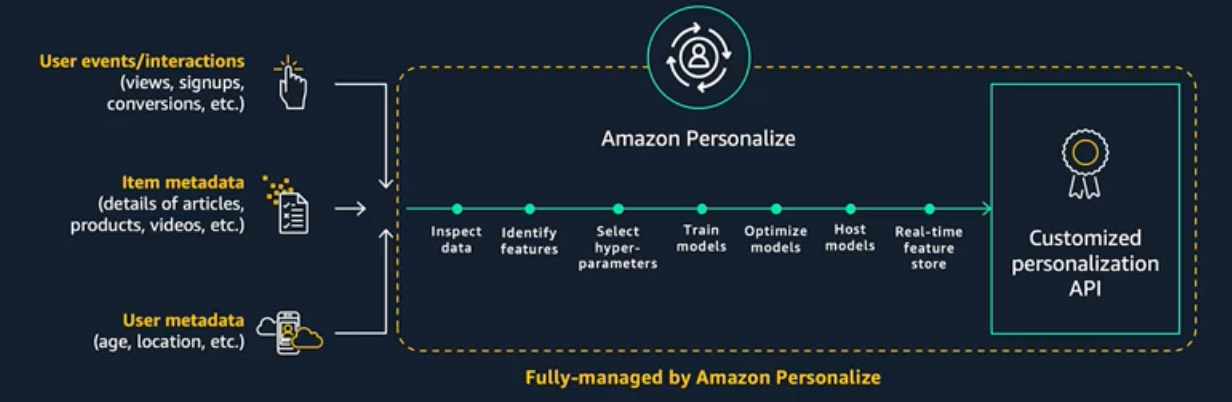
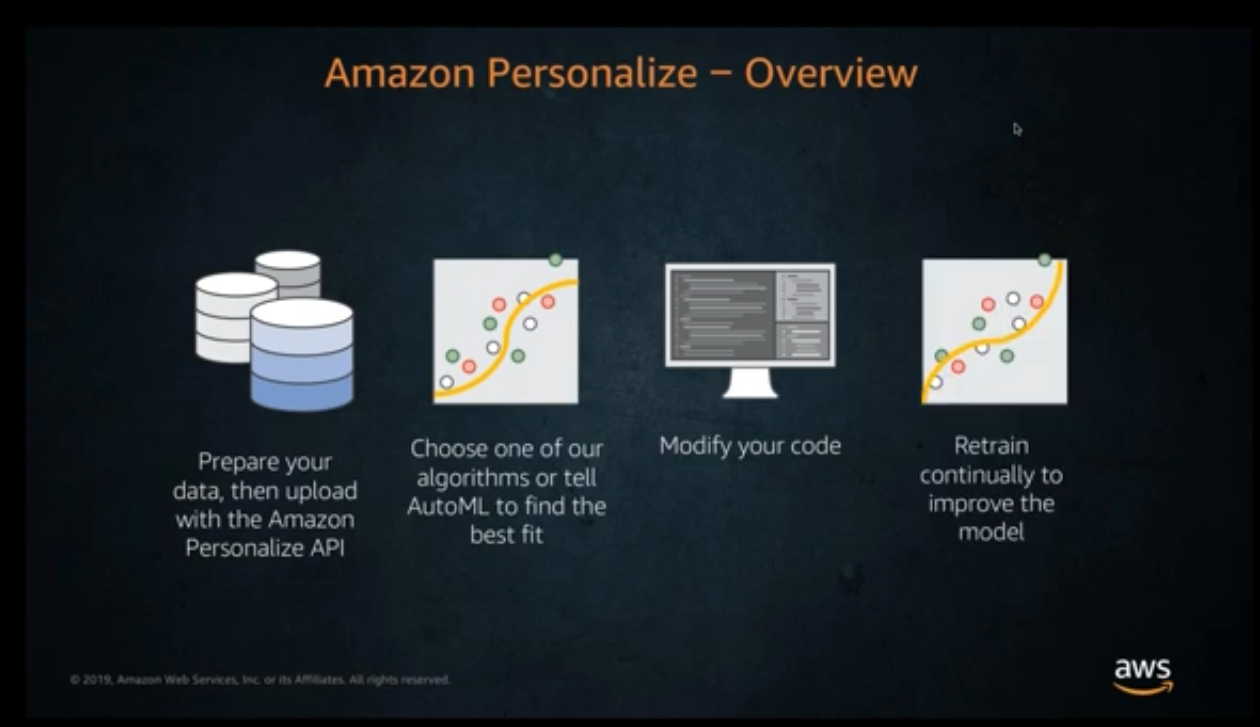
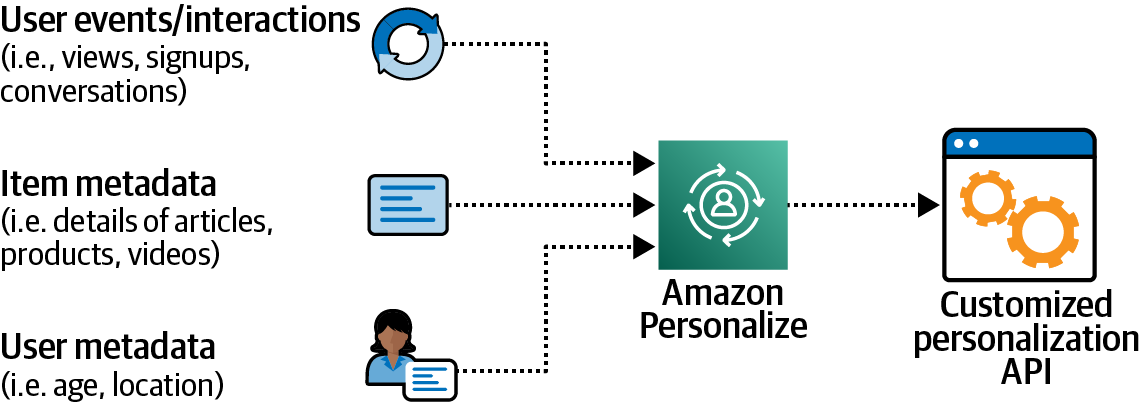
Amazon Personalize is a machine learning service that makes it easy for developers to create individualized recommendations for customers using their applications. With Amazon Personalize, you provide an activity stream from your application – clicks, page views, signups, purchases, and so forth – as well as an inventory of the items you want to recommend, such as articles, products, videos, or music. You can also choose to provide Amazon Personalize with additional demographic information from your users such as age, or geographic location. Amazon Personalize will process and examine the data, identify what is meaningful, select the right algorithms, and train and optimize a personalization model that is customized for your data. All data analyzed by Amazon Personalize is kept private and secure, and only used for your customized recommendations. You can start serving personalized recommendations via a simple API call. You pay only for what you use, and there are no minimum fees and no upfront commitments.
Personalize Recipes
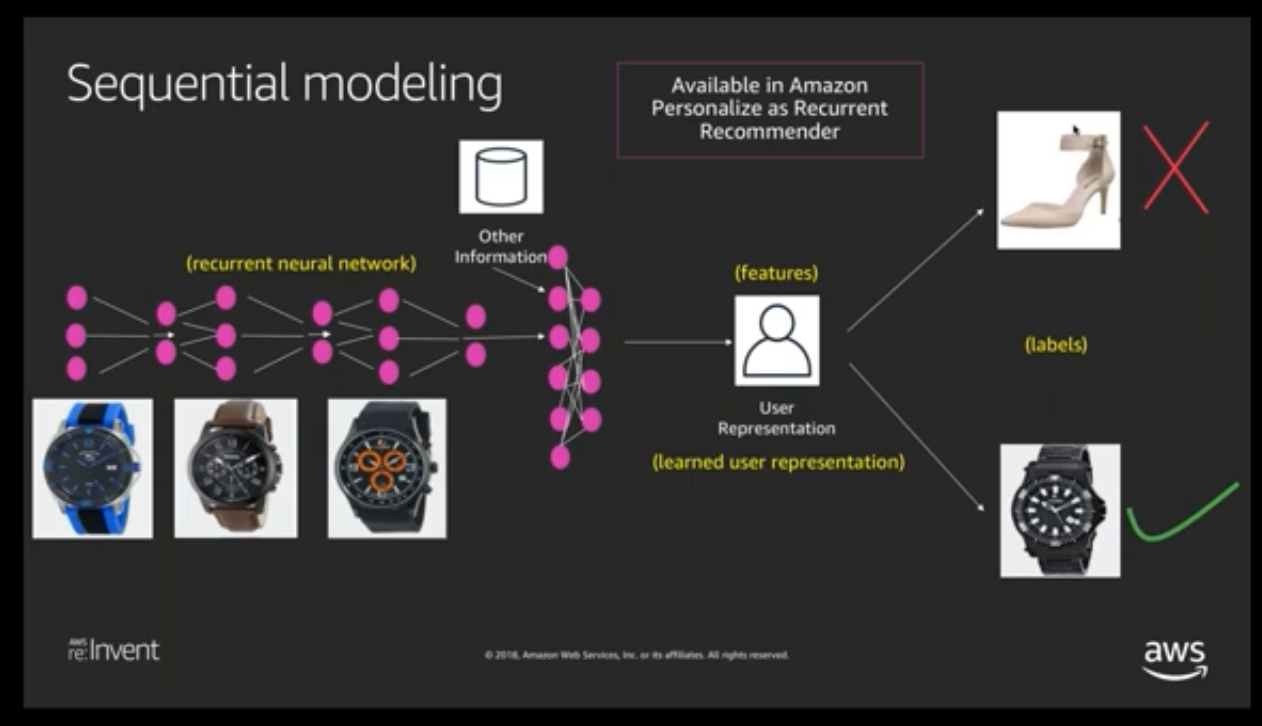
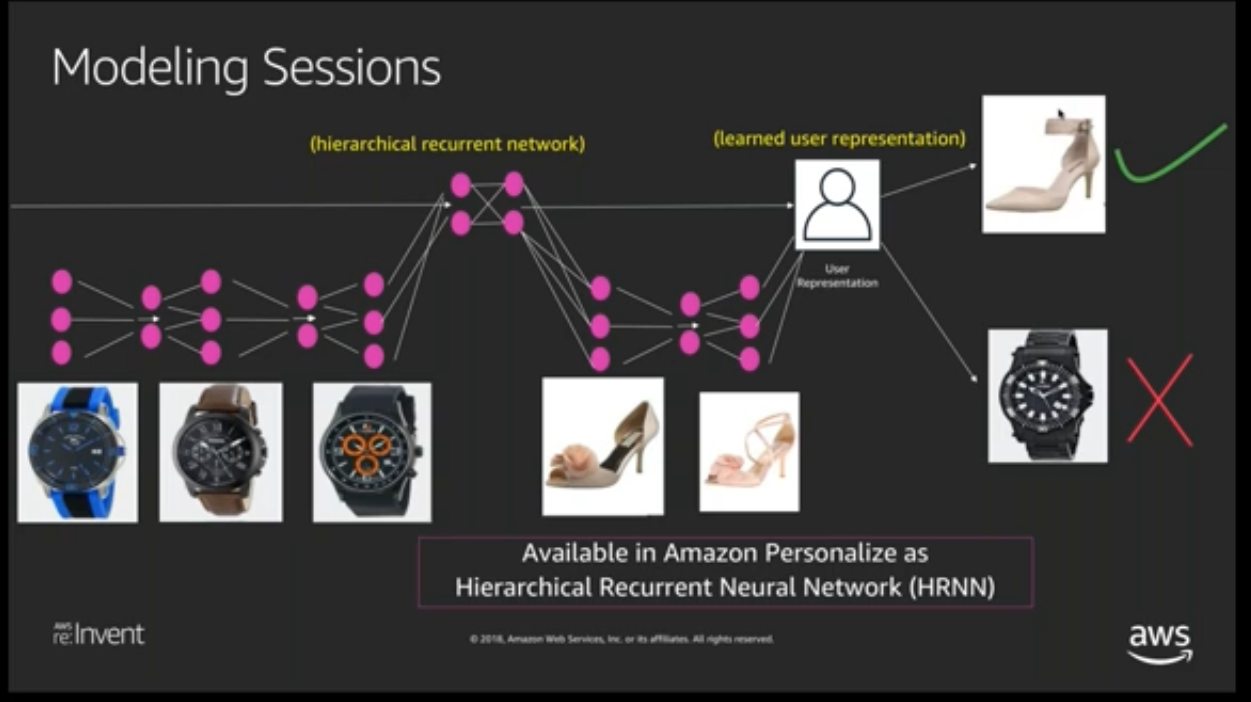
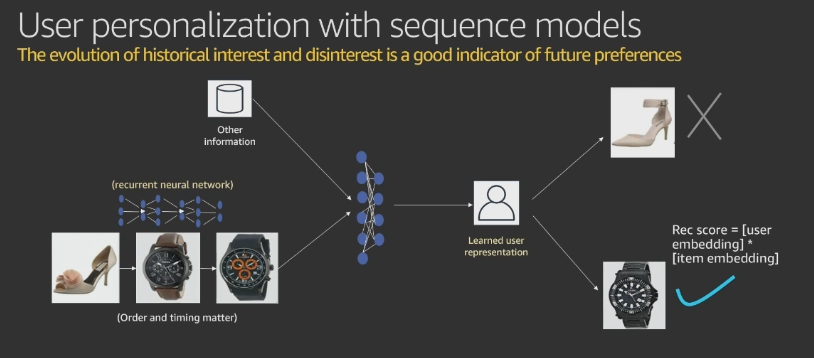
HRNN - Hierarchical recurrent neural network (HRNN), which is able to model the changes in user behavior.
HRNN-Metadata - Similar to the HRNN recipe with additional features derived from contextual, user, and item metadata (Interactions, Users, and Items datasets, respectively). Provides accuracy benefits over non-metadata models when high quality metadata is available.
HRNN-Coldstart - Similar to the HRNN-Metadata recipe, while adding personalized exploration of new items. Use this recipe when you are frequently adding new items to the Items dataset and require the items to immediately appear in the recommendations. Popularity-Count - Popularity-count returns the top popular items from a dataset. A popular item is defined by the number of times it occurs in the dataset. The recipe returns the same popular items for all users.
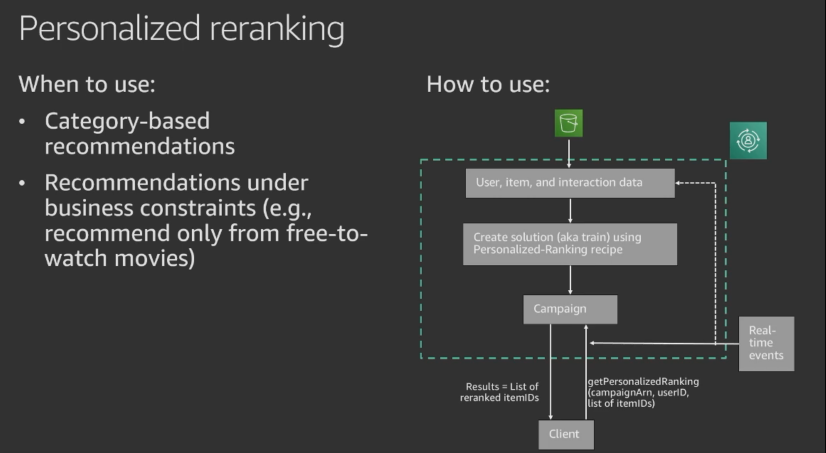
Personalized-Ranking - Provides a user with a ranked list of items.
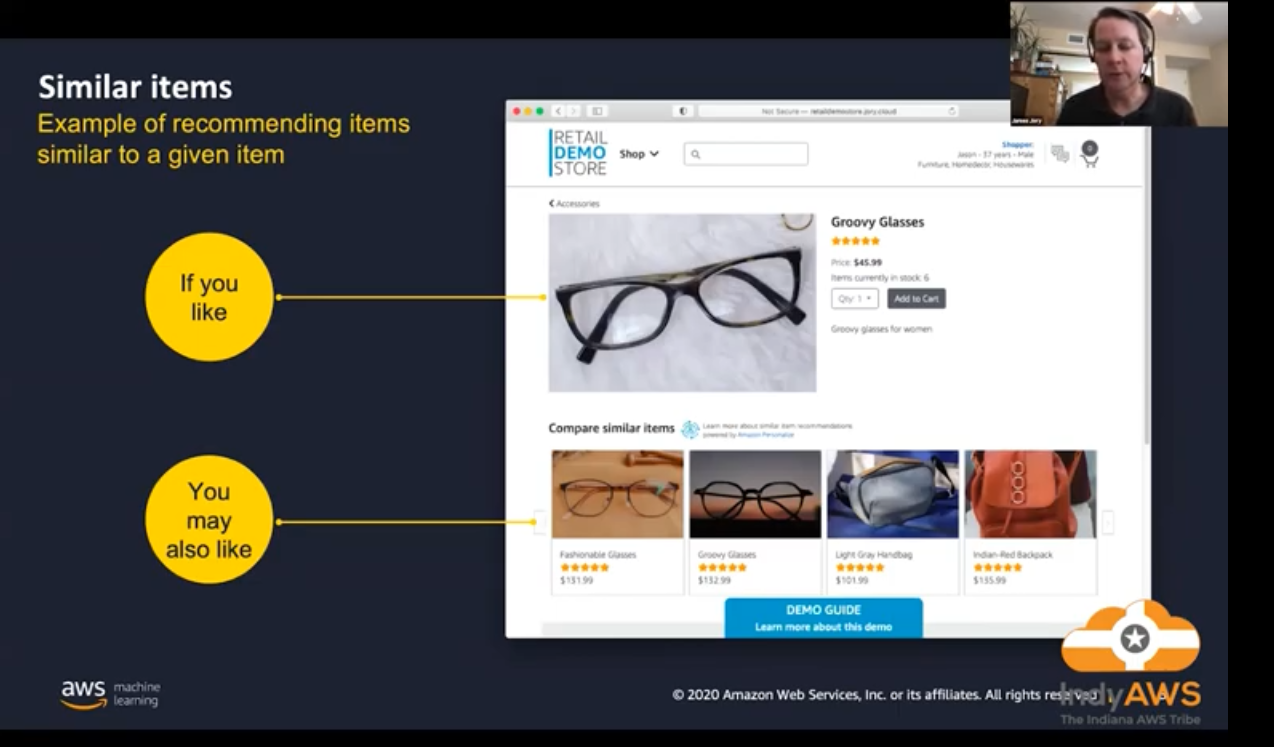
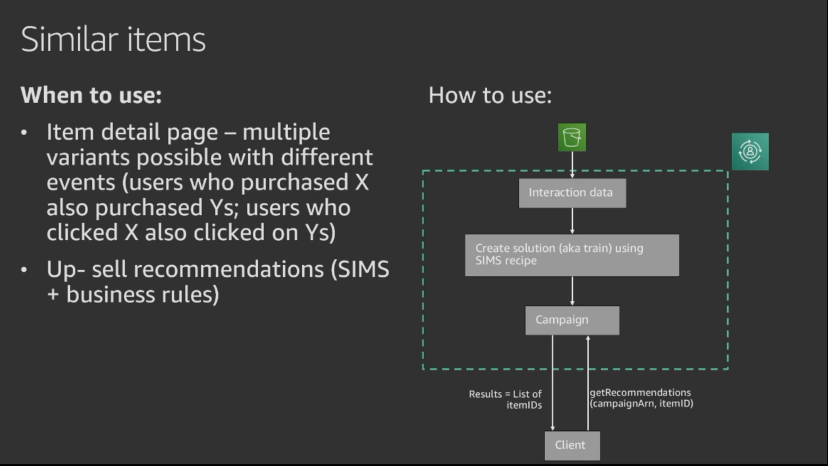
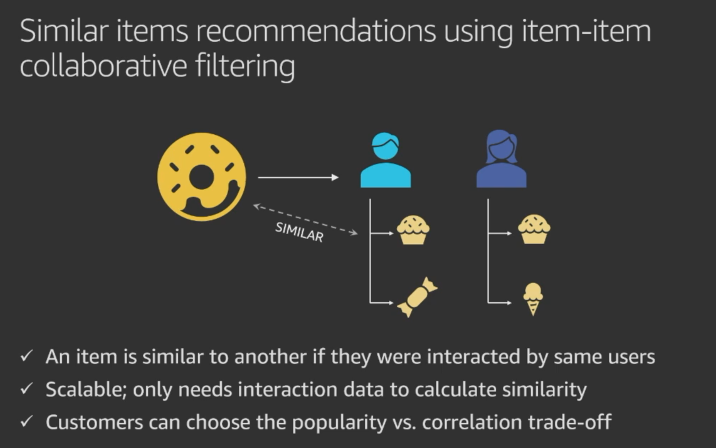
SIMS - Leverages user-item interaction data to recommend items similar to a given item. In the absence of sufficient user behavior data for an item, this recipe recommends popular items.
Limits of Amazon Personalize
It’s true that a powerful tool such as Amazon Personalize makes automatic most of the work required to set up a full working recommendation system. However, Amazon Personalize has still some limits which may with different degrees make this service less desirable for expert scientists and that could restrict the full performance of the model itself:
- Amazon Personalize is relatively slow: most of the operations involving Amazon Personalize takes time to complete. For example, creating a new dataset from the dashboard can take a few minutes while train a model can take hours depending on the size of the dataset but it takes long time even for small datasets. Finally, creating a campaign and a batch inference process also take several minutes.
- Input data should follow a specific format: although using Amazon Personalize doesn’t require any machine learning knowledge, however, a team of data scientists is still required to handle the data pre-processing which could be a very time and resource consuming process.
- Amazon Personalize accepts a maximum of 5 features per user: consequently, should be used any feature selection algorithm to estimate features’ importance and select the 5 most useful ones.
- Comparison is not straight-forward: The fact that Amazon Personalize selects a random test set makes it difficult the comparison with other models with the metrics provided by the system. Thus, we had first to make predictions on the test set, process the result, and manually compute the metrics.
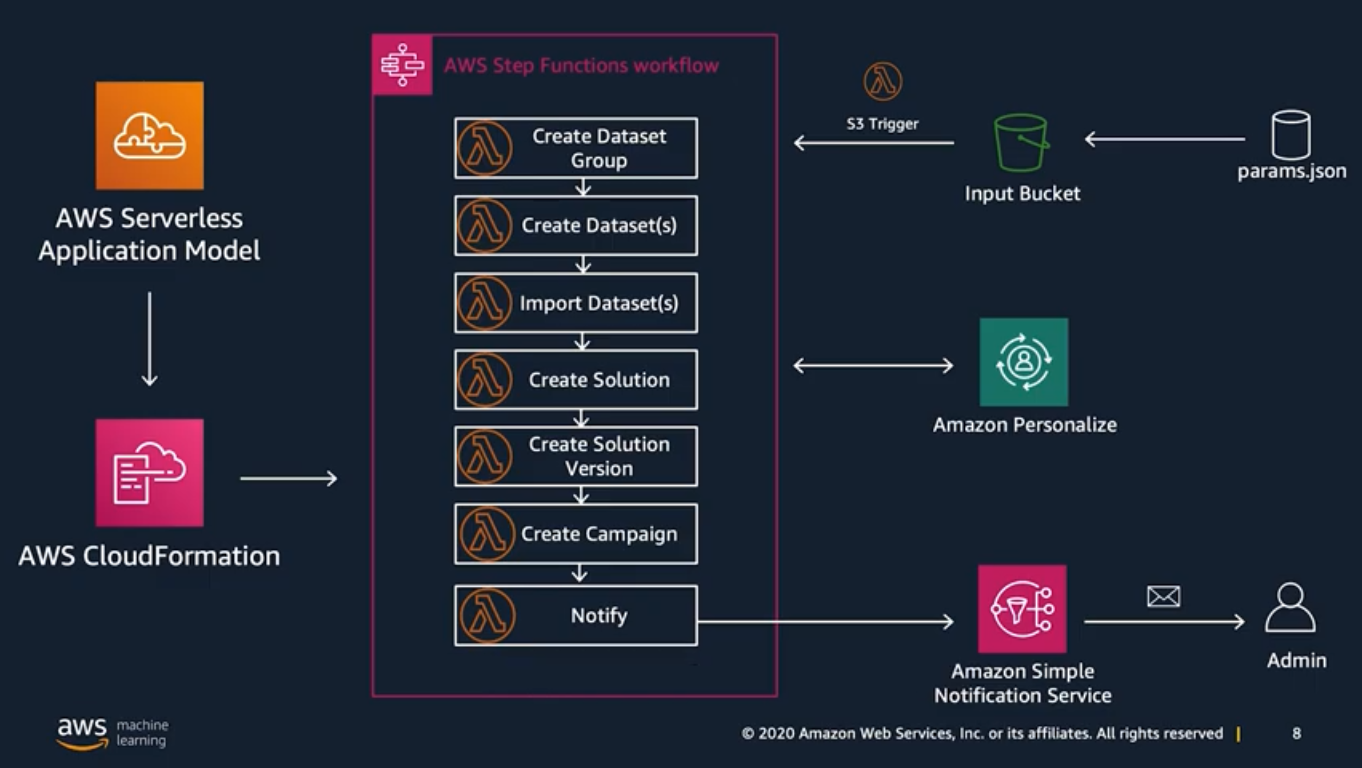
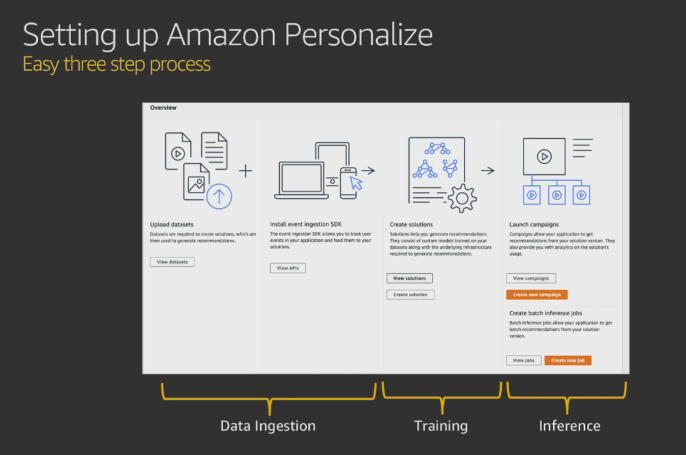
Amazon Personalize Workflow
The general workflow for training, deploying, and getting recommendations from a campaign is as follows:
- Prepare data
- Create related datasets and a dataset group.
- Get training data.
- Import historical data to the dataset group.
- Record user events to the dataset group.
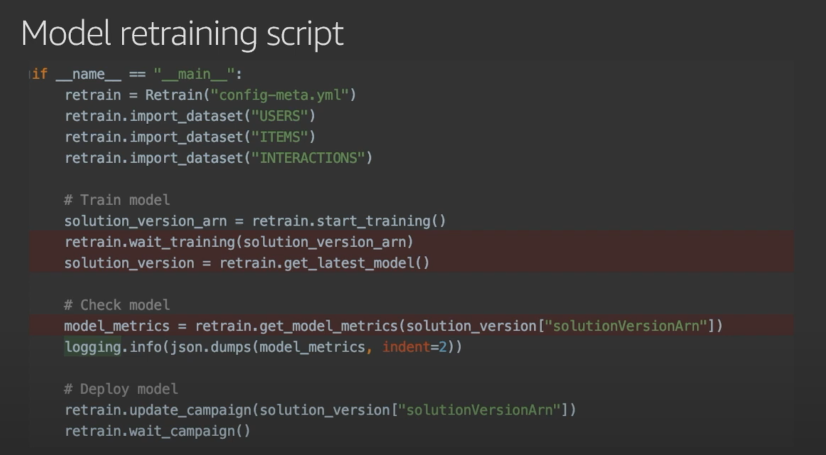
- Create a solution version (trained model) using a recipe.
- Evaluate the solution version using metrics.
- Create a campaign (deploy the solution version).
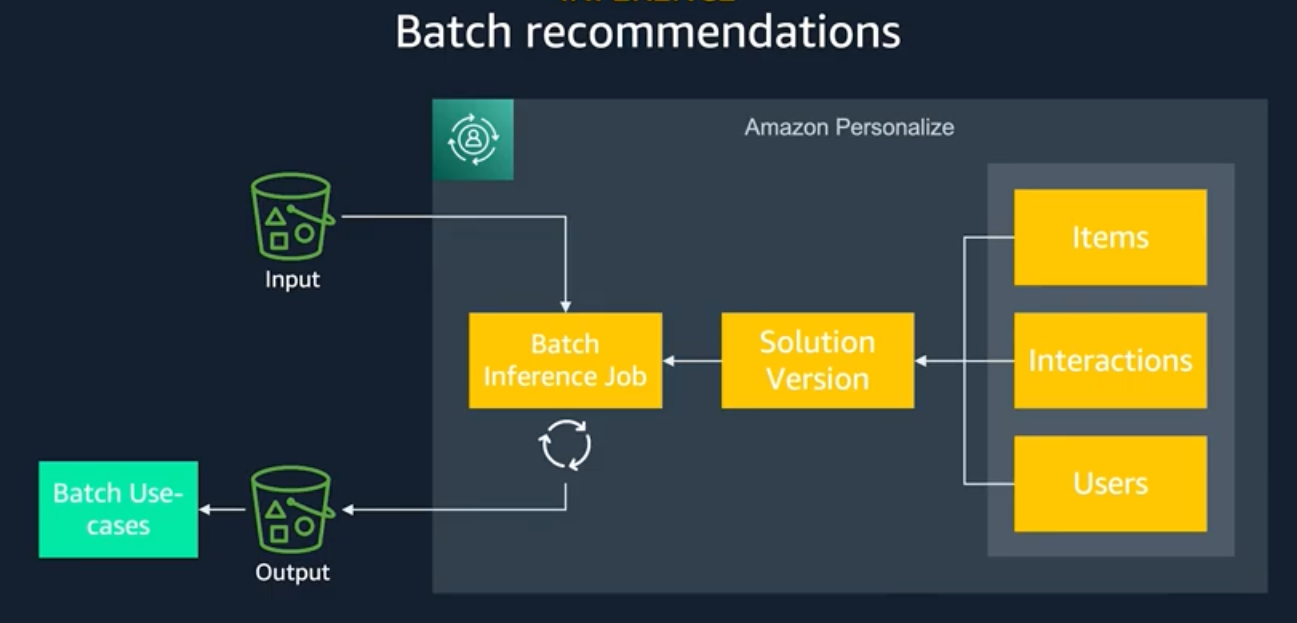
- Provide recommendations for users by running Batch or Real-time Recommendation.
Learnings
- How to map datasets to Amazon Personalize.
- Which models or recipes are appropriate for which use cases.
- How to build models in a programmatic fashion.
- How to interpret model metrics.
- How to deploy models in a programmatic fashion.
- How to obtain results from Personalize.
For the most part, the algorithms in Amazon Personalize (called recipes) look to solve different tasks, explained here:
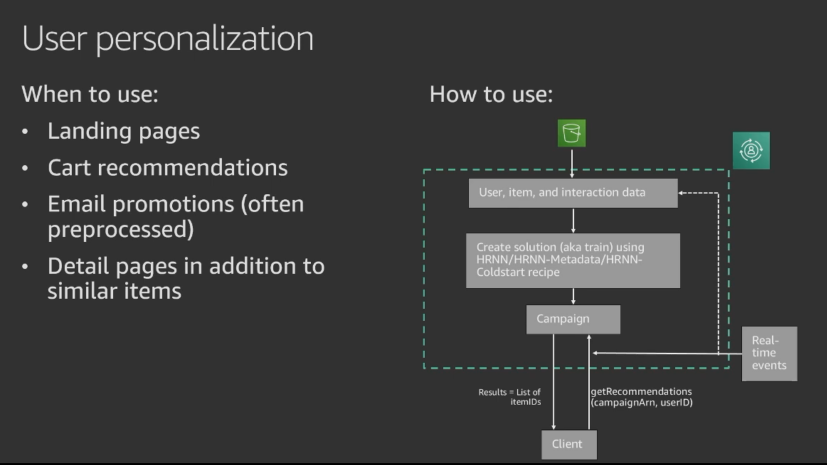
- User Personalization - New release that supports ALL HRNN workflows / user personalization needs, it will be what we use here.
- HRNN & HRNN-Metadata - Recommends items based on previous user interactions with items.
- HRNN-Coldstart - Recommends new items for which interaction data is not yet available.
- Personalized-Ranking - Takes a collection of items and then orders them in probable order of interest using an HRNN-like approach.
- SIMS (Similar Items) - Given one item, recommends other items also interacted with by users.
- Popularity-Count - Recommends the most popular items, if HRNN or HRNN-Metadata do not have an answer - this is returned by default.
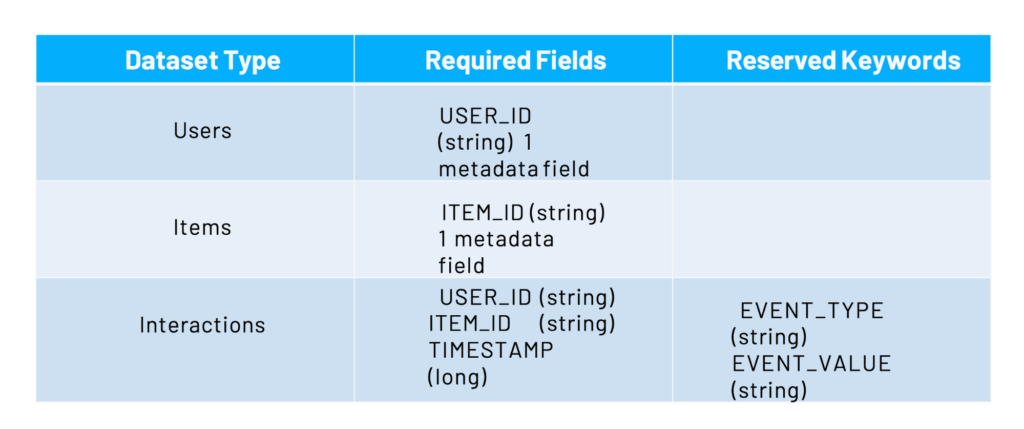
No matter the use case, the algorithms all share a base of learning on user-item-interaction data which is defined by 3 core attributes:
- UserID - The user who interacted
- ItemID - The item the user interacted with
- Timestamp - The time at which the interaction occurred
We also support event types and event values defined by:
- Event Type - Categorical label of an event (browse, purchased, rated, etc).
- Event Value - A value corresponding to the event type that occurred. Generally speaking, we look for normalized values between 0 and 1 over the event types. For example, if there are three phases to complete a transaction (clicked, added-to-cart, and purchased), then there would be an event_value for each phase as 0.33, 0.66, and 1.0 respectfully.
The event type and event value fields are additional data which can be used to filter the data sent for training the personalization model.
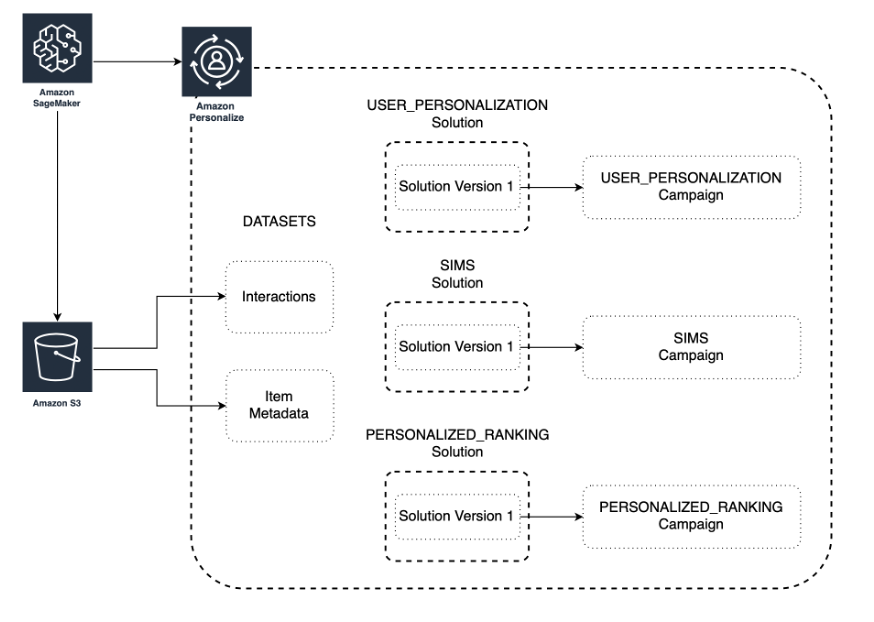
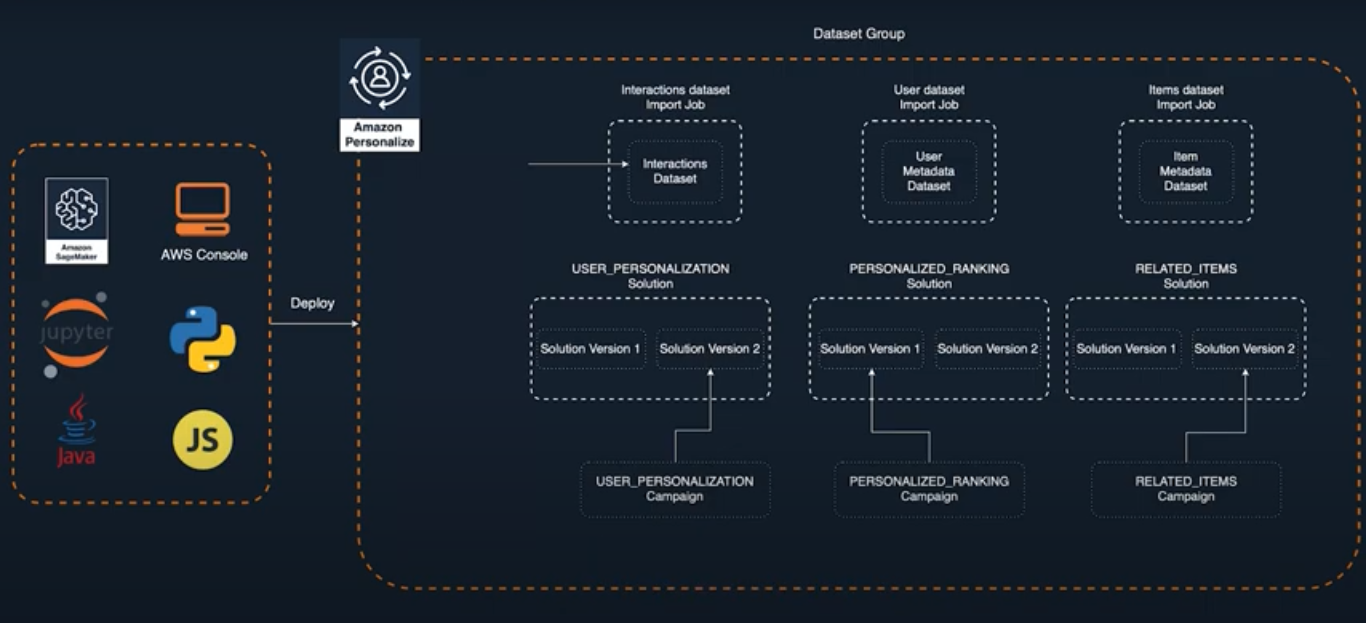
Dataset group
The highest level of isolation and abstraction with Amazon Personalize is a dataset group. Information stored within one of these dataset groups has no impact on any other dataset group or models created from one - they are completely isolated. This allows you to run many experiments and is part of how we keep your models private and fully trained only on your data.
Evaluation
We recommend reading the documentation to understand the metrics, but we have also copied parts of the documentation below for convenience.
You need to understand the following terms regarding evaluation in Personalize:
- Relevant recommendation refers to a recommendation that matches a value in the testing data for the particular user.
- Rank refers to the position of a recommended item in the list of recommendations. Position 1 (the top of the list) is presumed to be the most relevant to the user.
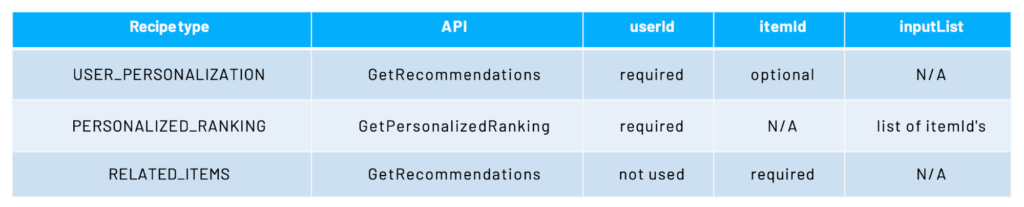
- Query refers to the internal equivalent of a GetRecommendations call.
The metrics produced by Personalize are:
- coverage: The proportion of unique recommended items from all queries out of the total number of unique items in the training data (includes both the Items and Interactions datasets).
- mean_reciprocal_rank_at_25: The mean of the reciprocal ranks of the first relevant recommendation out of the top 25 recommendations over all queries. This metric is appropriate if you're interested in the single highest ranked recommendation.
- normalized_discounted_cumulative_gain_at_K: Discounted gain assumes that recommendations lower on a list of recommendations are less relevant than higher recommendations. Therefore, each recommendation is discounted (given a lower weight) by a factor dependent on its position. To produce the cumulative discounted gain (DCG) at K, each relevant discounted recommendation in the top K recommendations is summed together. The normalized discounted cumulative gain (NDCG) is the DCG divided by the ideal DCG such that NDCG is between 0 - 1. (The ideal DCG is where the top K recommendations are sorted by relevance.) Amazon Personalize uses a weighting factor of 1/log(1 + position), where the top of the list is position 1. This metric rewards relevant items that appear near the top of the list, because the top of a list usually draws more attention.
- precision_at_K: The number of relevant recommendations out of the top K recommendations divided by K. This metric rewards precise recommendation of the relevant items.
Using evaluation metrics
It is important to use evaluation metrics carefully. There are a number of factors to keep in mind.
- If there is an existing recommendation system in place, this will have influenced the user's interaction history which you use to train your new solutions. This means the evaluation metrics are biased to favor the existing solution. If you work to push the evaluation metrics to match or exceed the existing solution, you may just be pushing the User Personalization to behave like the existing solution and might not end up with something better.
- The HRNN Coldstart recipe is difficult to evaluate using the metrics produced by Amazon Personalize. The aim of the recipe is to recommend items which are new to your business. Therefore, these items will not appear in the existing user transaction data which is used to compute the evaluation metrics. As a result, HRNN Coldstart will never appear to perform better than the other recipes, when compared on the evaluation metrics alone. Note: The User Personalization recipe also includes improved cold start functionality
Keeping in mind these factors, the evaluation metrics produced by Personalize are generally useful for two cases:
- Comparing the performance of solution versions trained on the same recipe, but with different values for the hyperparameters and features (impression data etc)
- Comparing the performance of solution versions trained on different recipes (except HRNN Coldstart).
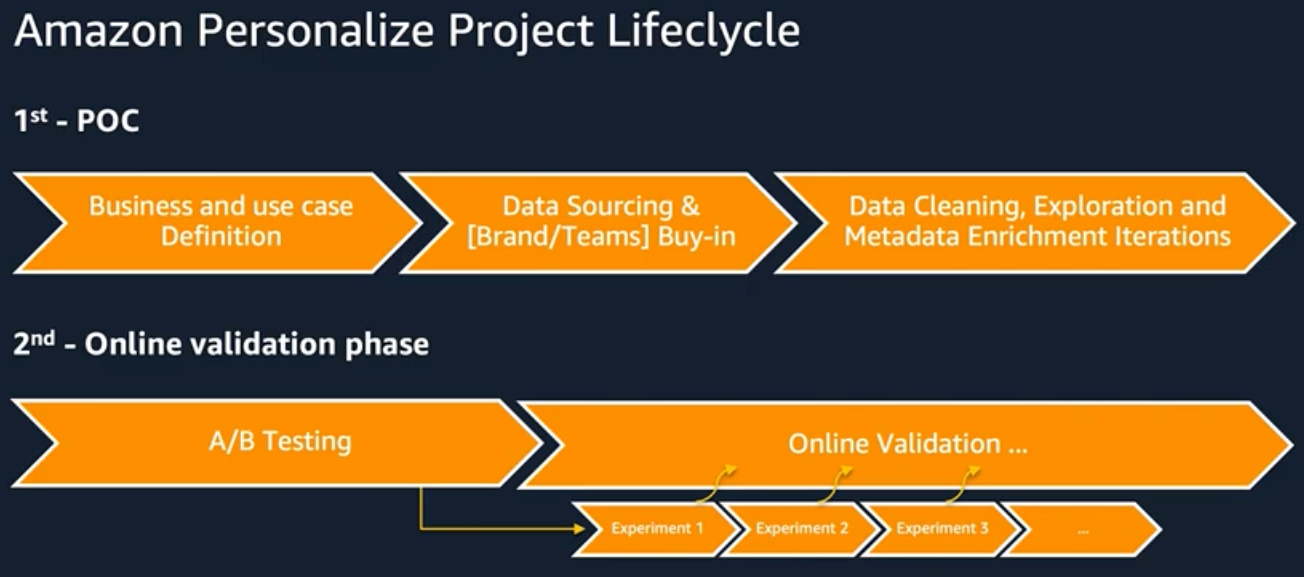
Properly evaluating a recommendation system is always best done through A/B testing while measuring actual business outcomes. Since recommendations generated by a system usually influence the user behavior which it is based on, it is better to run small experiments and apply A/B testing for longer periods of time. Over time, the bias from the existing model will fade.
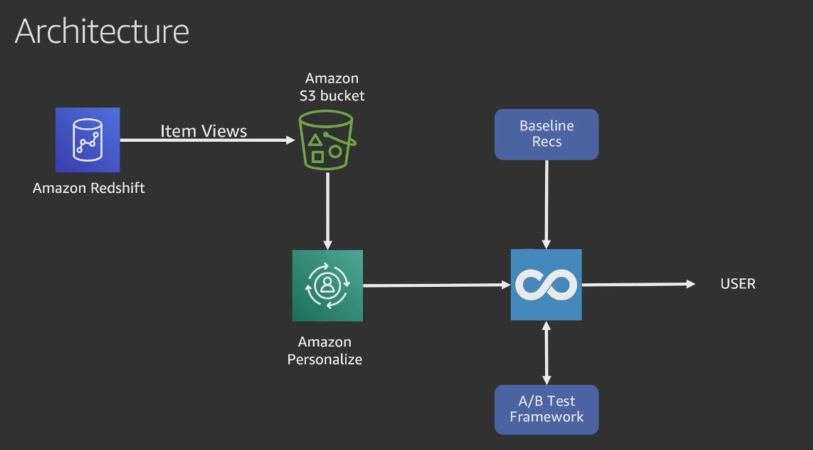
The effectiveness of machine learning models is directly tied to the quantity and quality of data input during the training process. For most personalization ML solutions, training data typically comes from clickstream data collected from websites, mobile applications, and other online & offline channels where end-users are interacting with items for which we wish to make recommendations. Examples of clickstream events include viewing items, adding items to a list or cart, and purchasing items. Although an Amazon Personalize Campaign can be started with just new clickstream data, the initial quality of the recommendations will not be as high as a model that has been trained on recent historical data.
Amazon Personalize Notes v2


MLOps - Automate the Recommenders



Amazon Personalize Notes v1
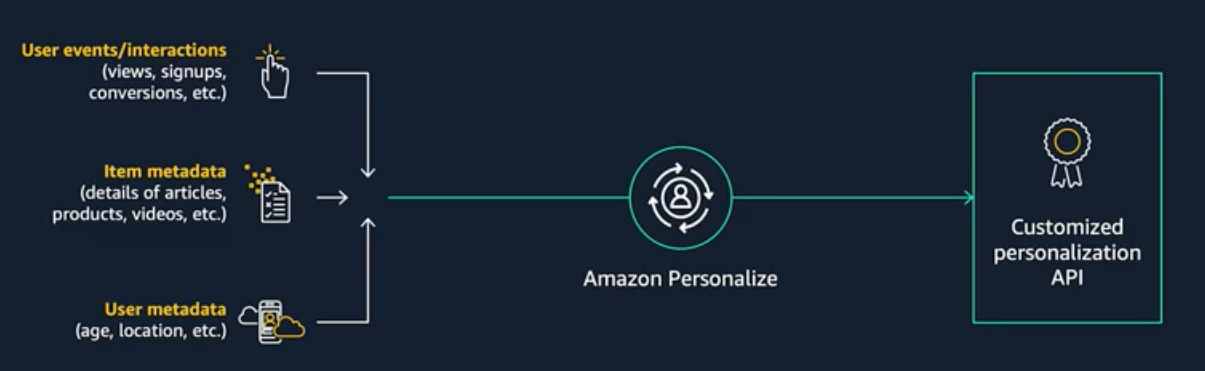
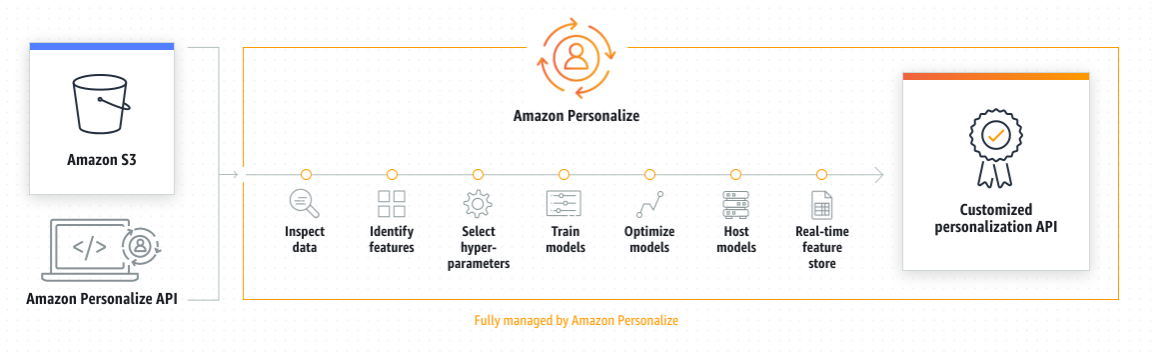


Popular Use-cases
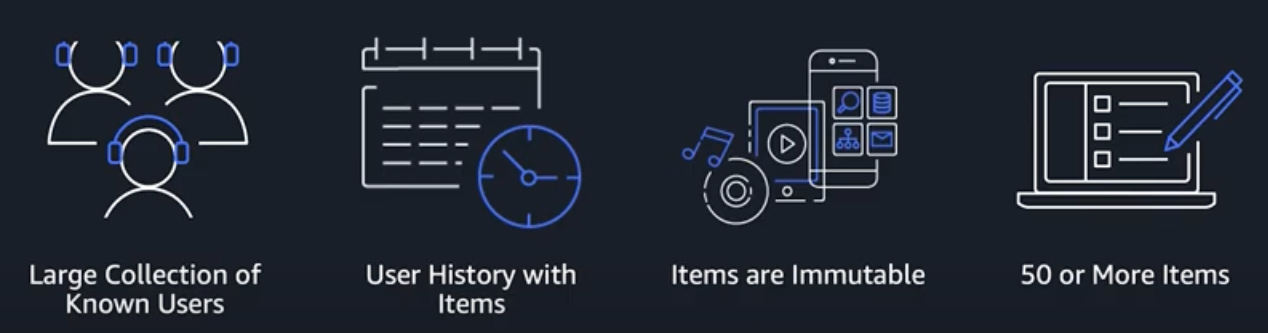
Dataset Characteristics

MLOps - Automate the Recommenders
"Deep Dive on Amazon Personalize" by: James Jory
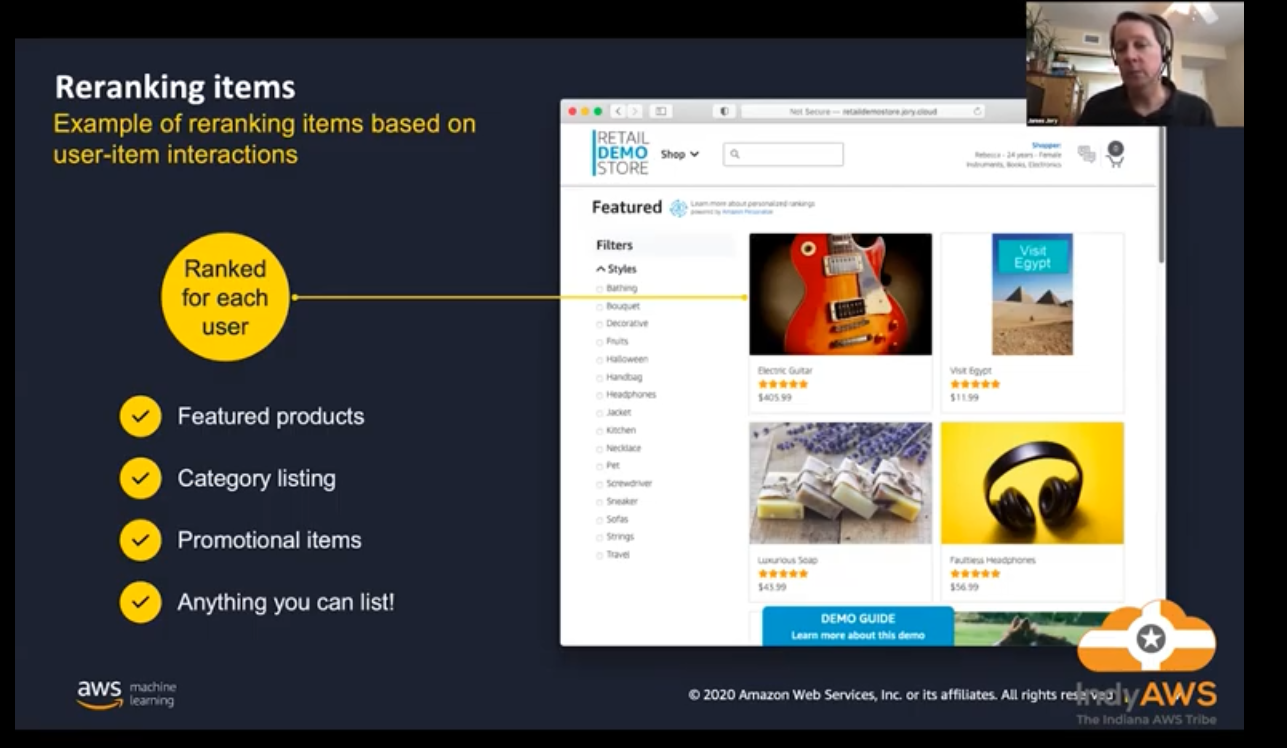

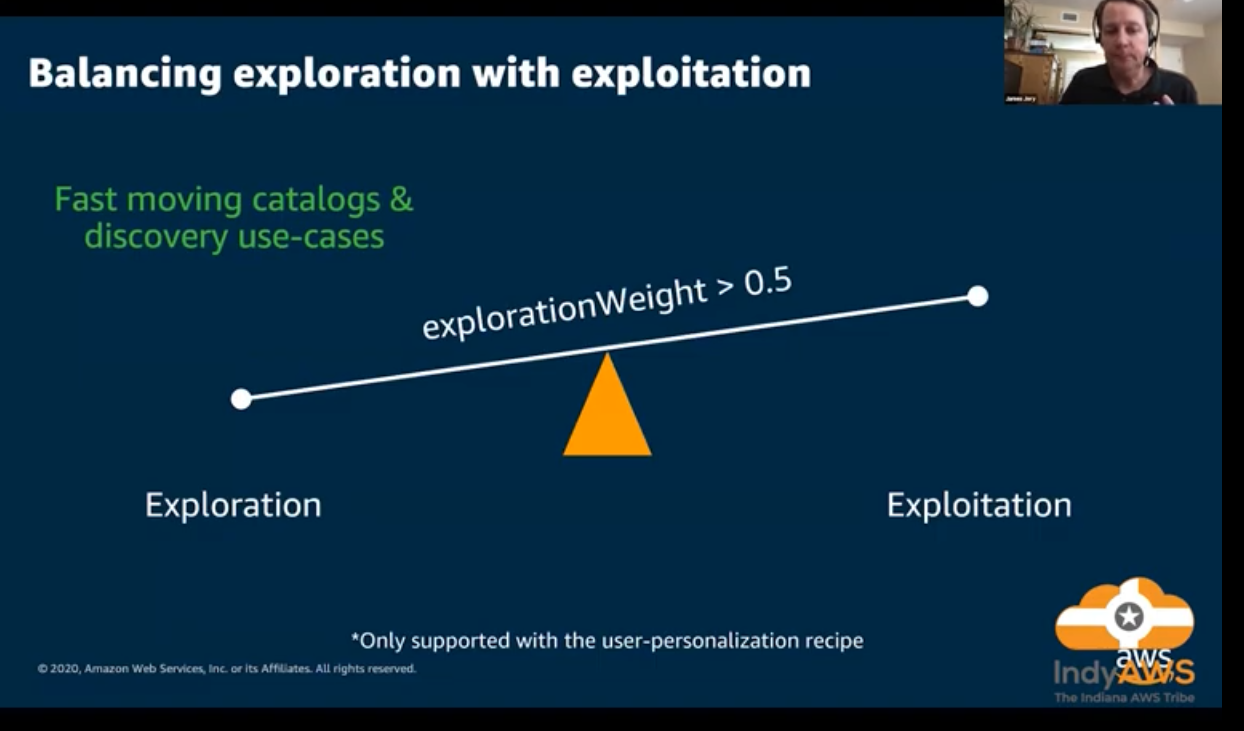
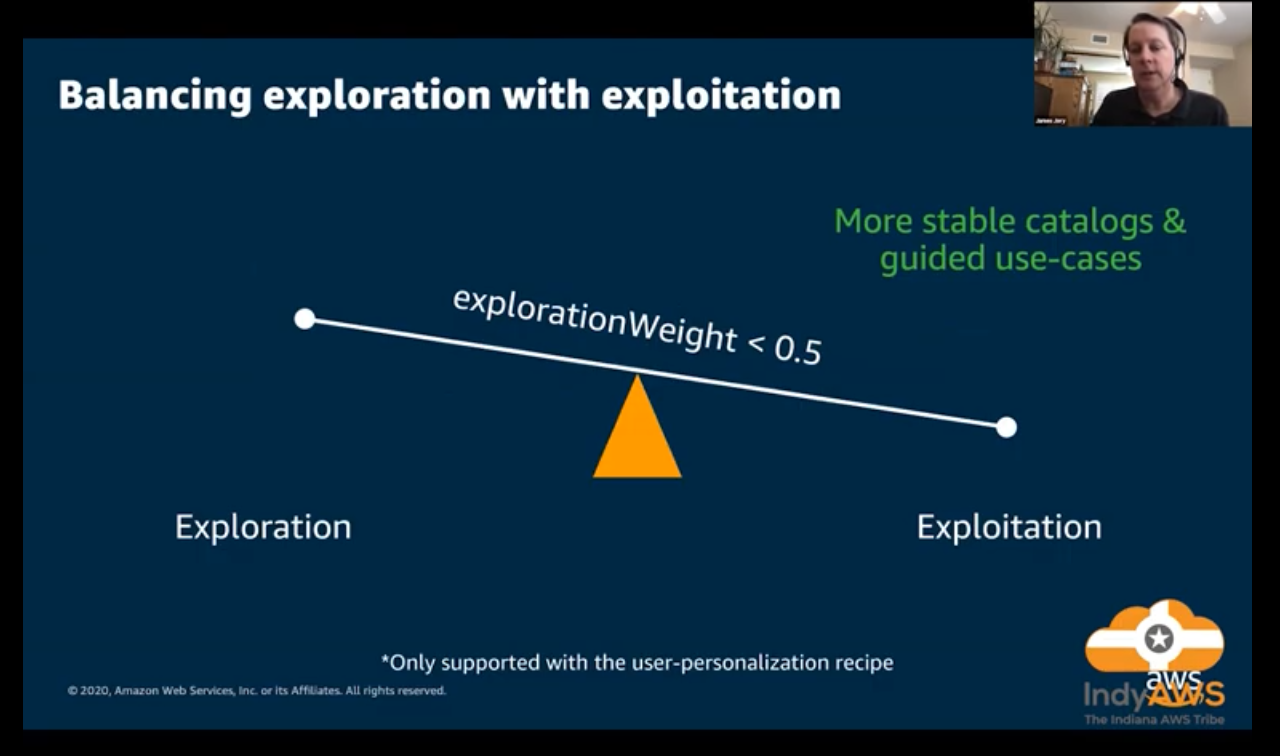
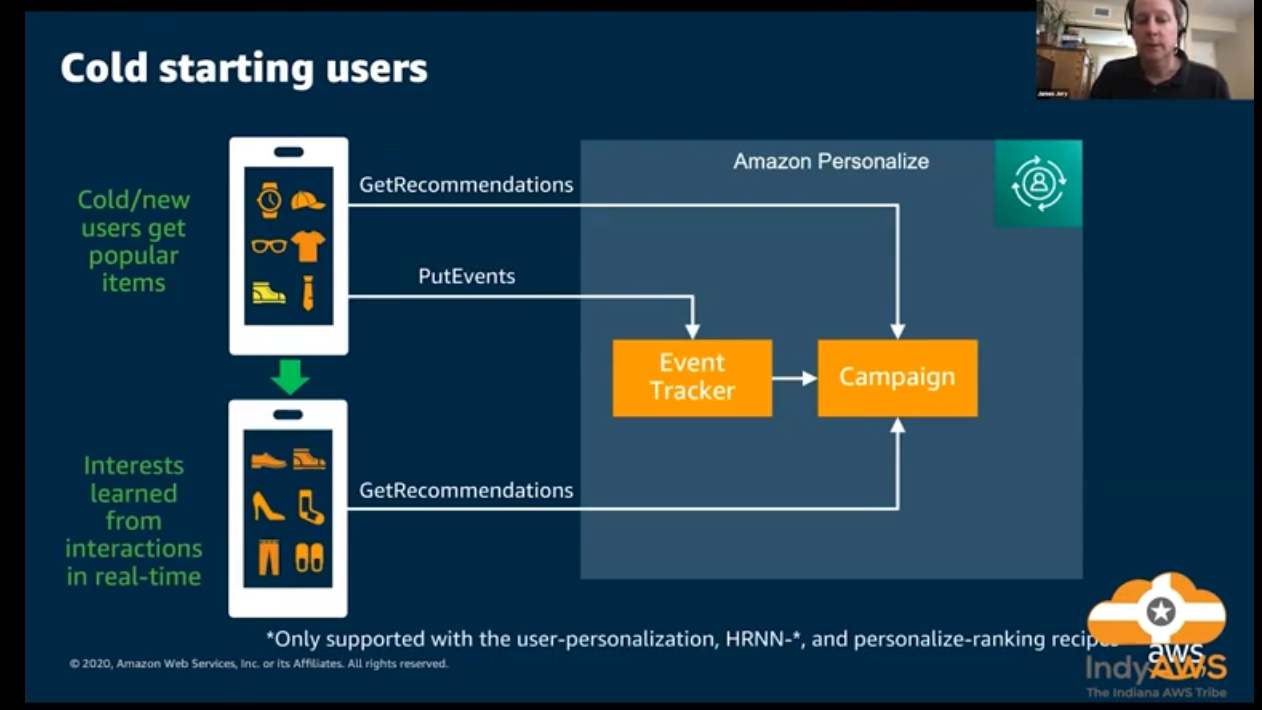
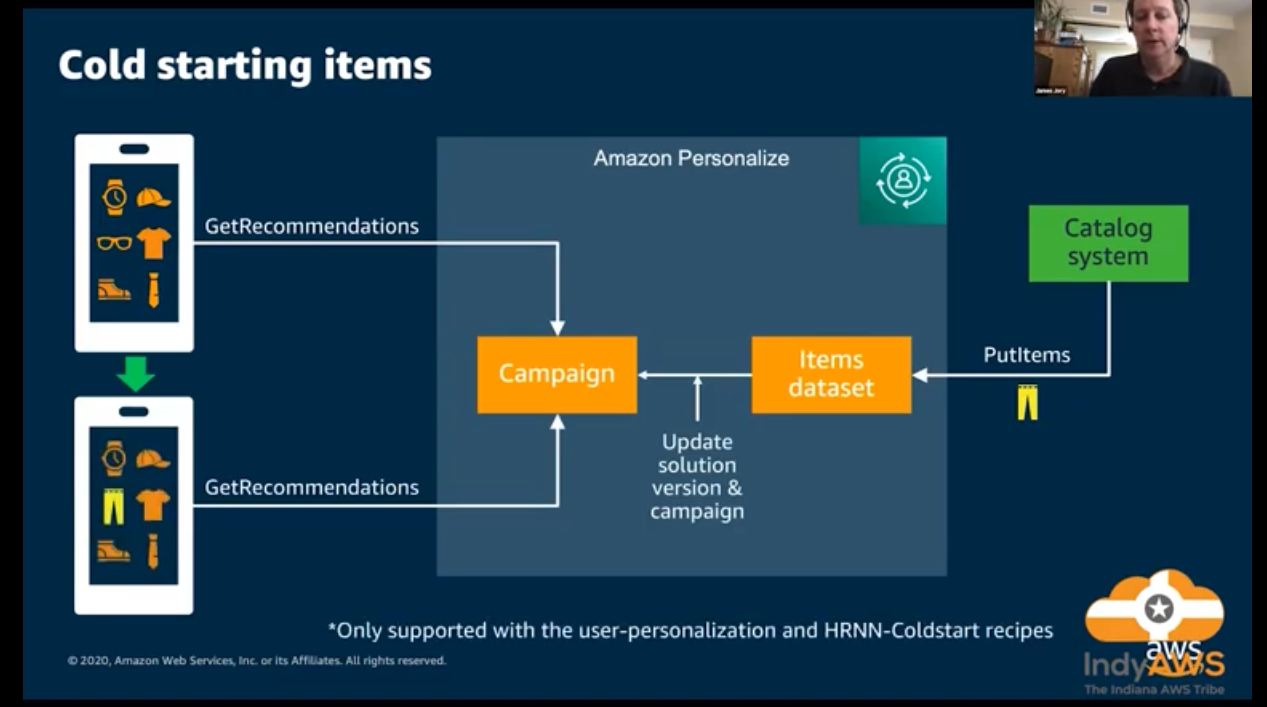

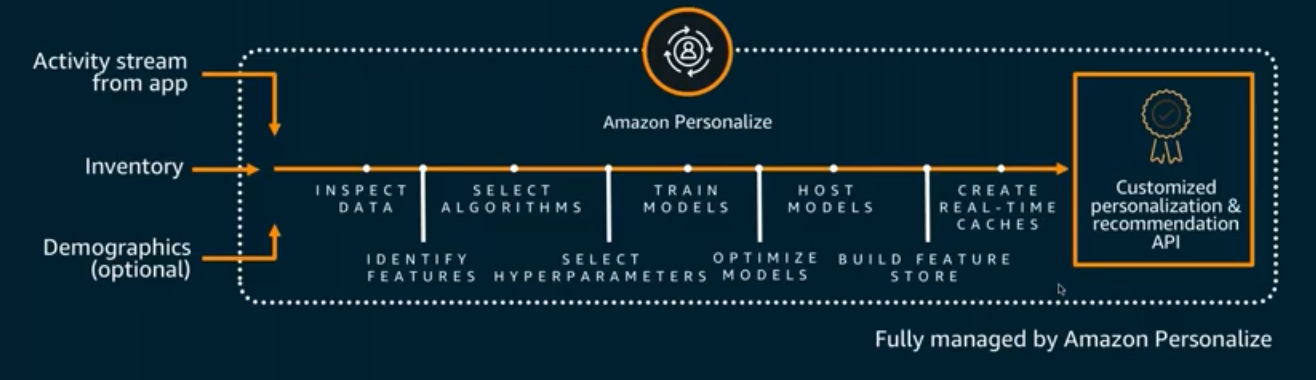
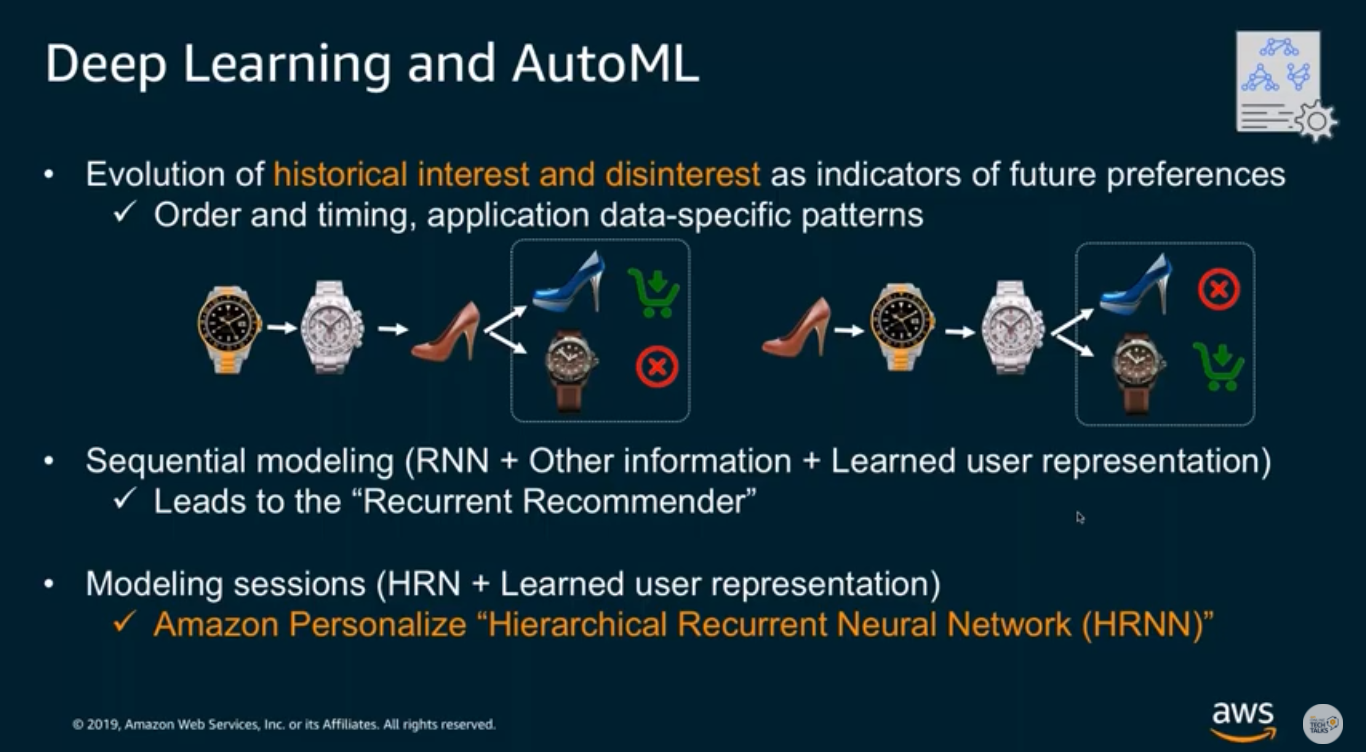
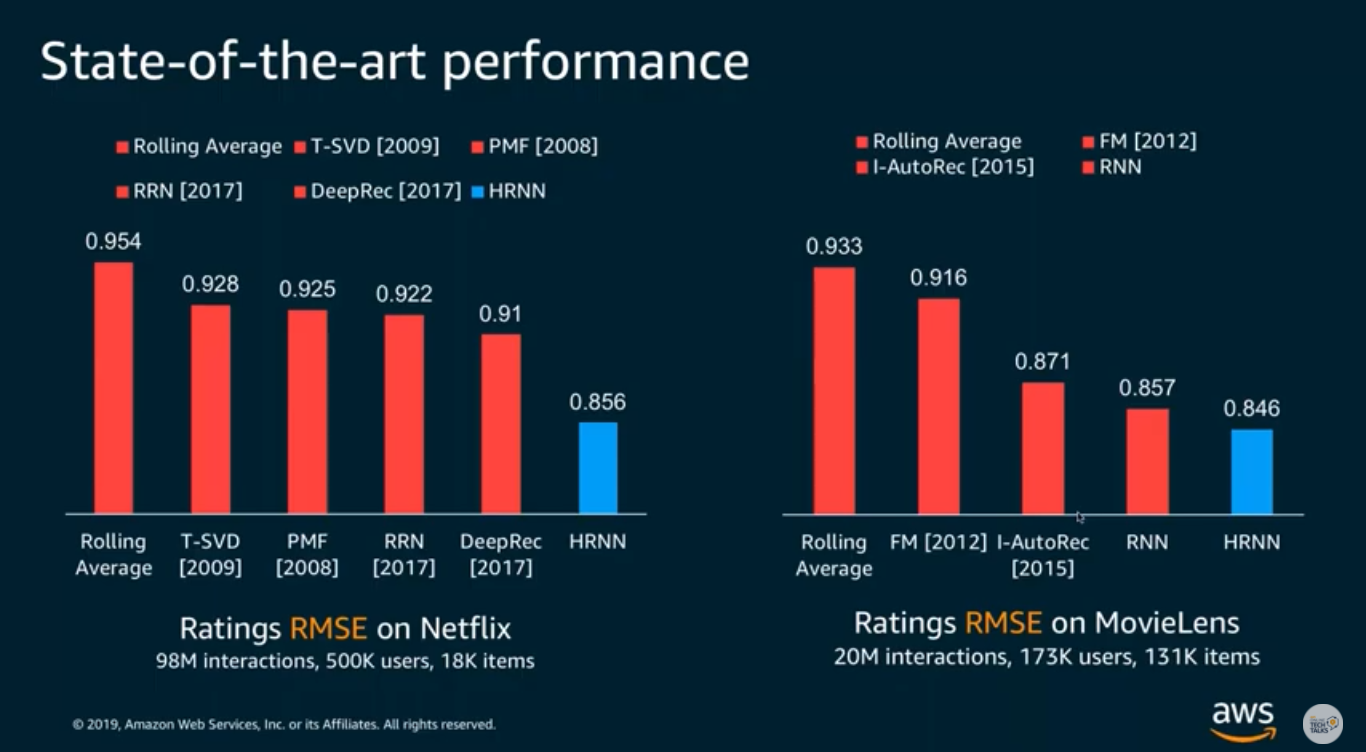

](/ai-kb/assets/images/content-concepts-raw-amazon-personalize-untitled-35-1b15a6a27f349213bc3b09667c39b18b.png)
https://www.personalisevideorecs.info/recommend/
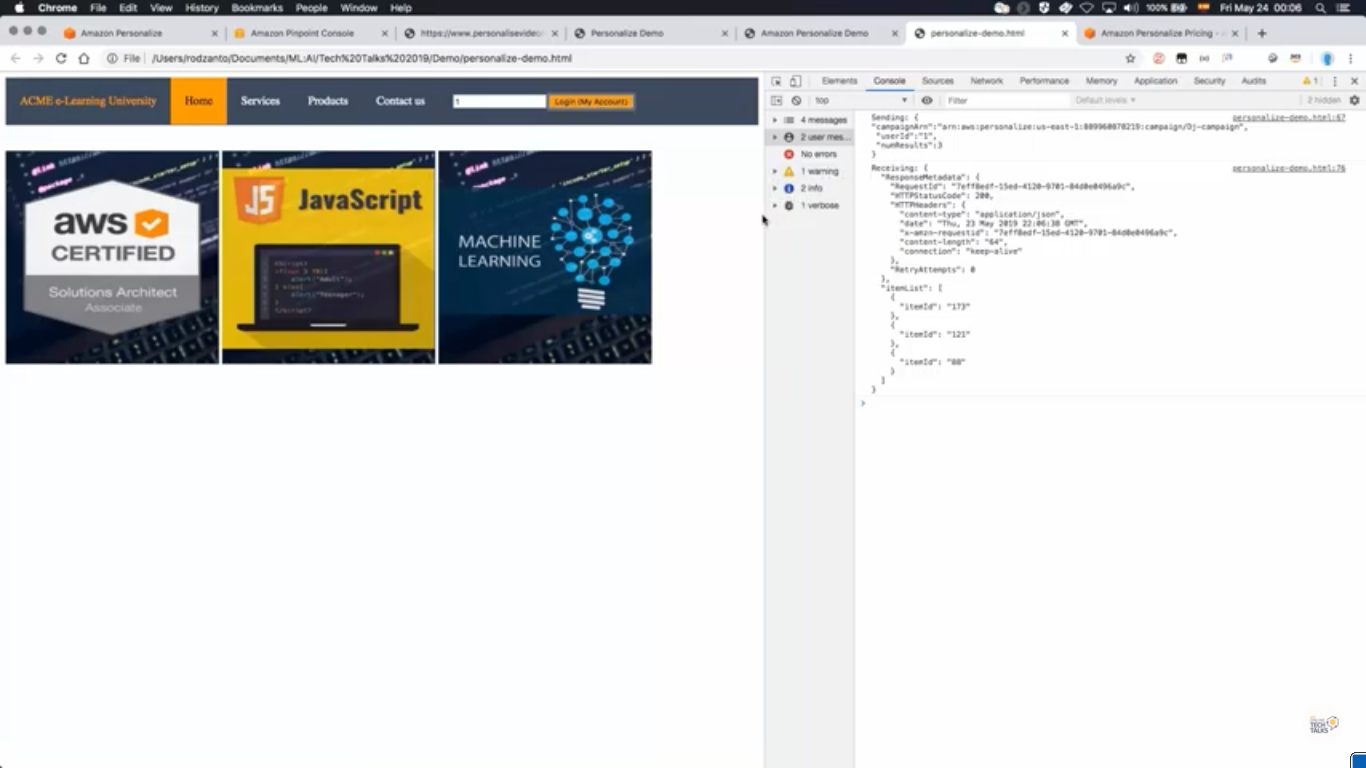









get_recommendations_response = personalize_runtime.get_recommendations(
campaignArn = campaign_arn,
userId = user_id
)
item_list = get_recommendations_response['itemList']
recommendation_list = []
for item in item_list:
item_id = get_movie_by_id(item['itemId'])
recommendation_list.append(item_id)

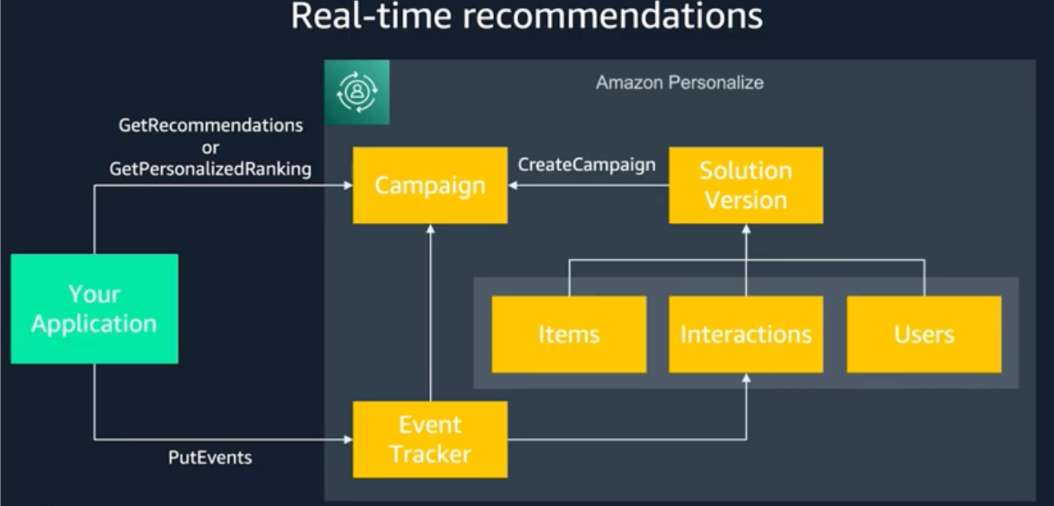
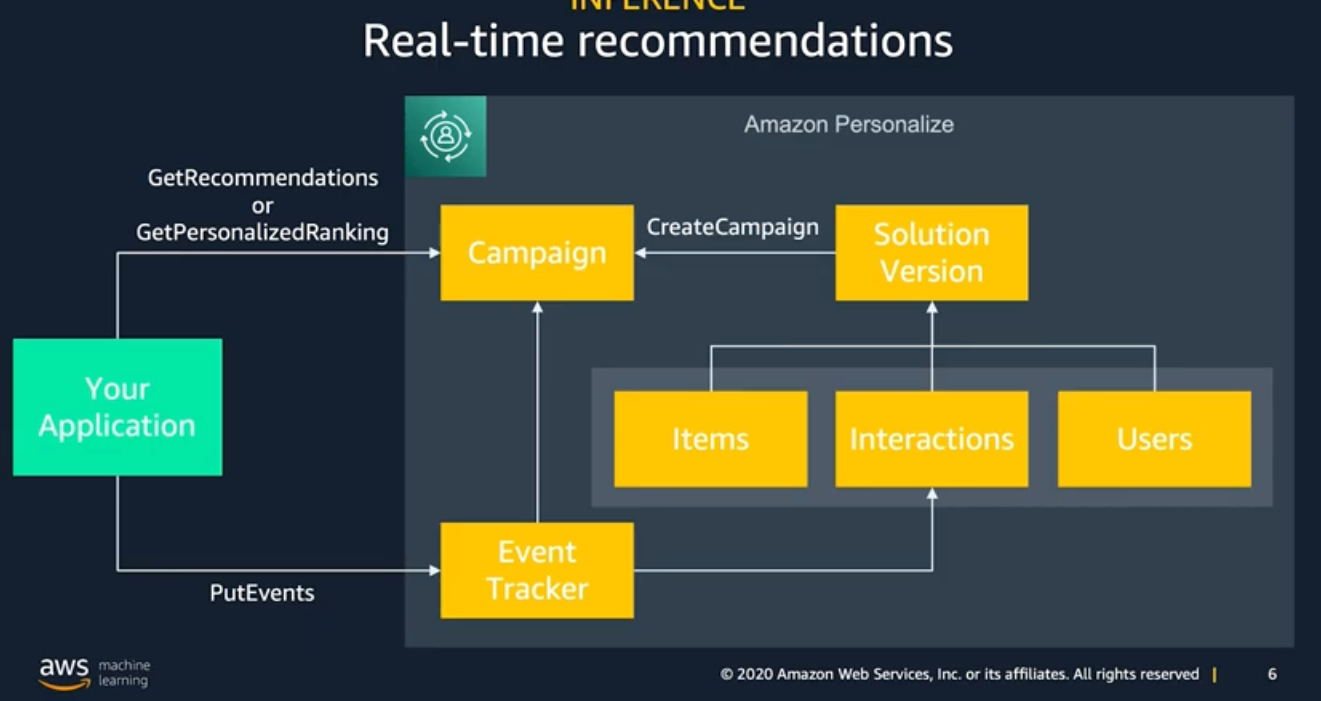
Amazon Personalize consists of three components:
- Amazon Personalize – used to create, manage and deploy solution versions.
- Amazon Personalize events – used to record user events for training data.
- Amazon Personalize Runtime – used to get recommendations from a campaign.
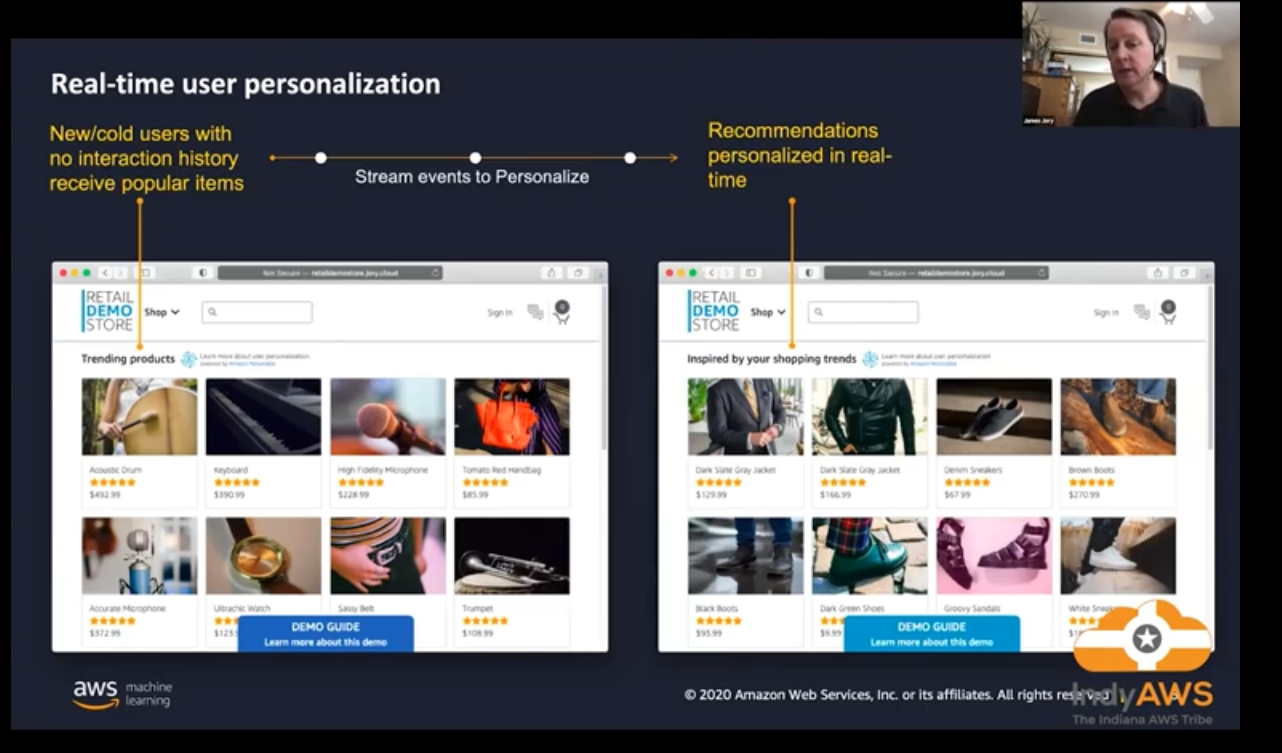
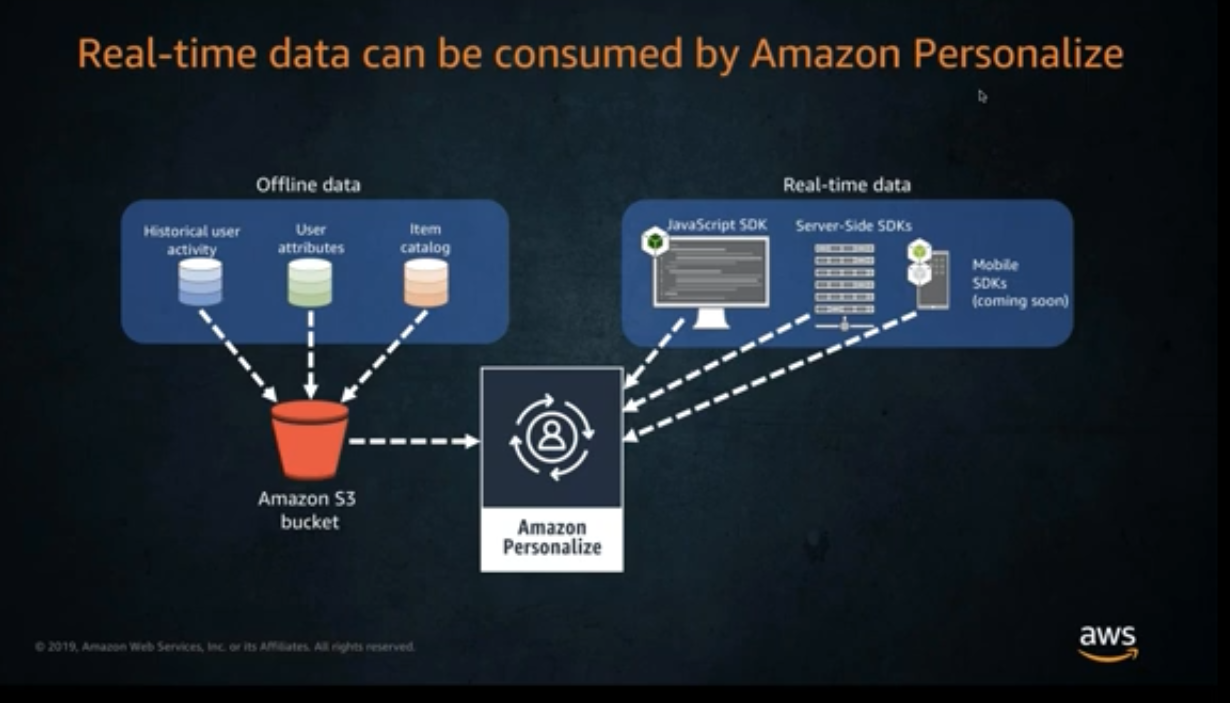
Amazon Personalize can utilize real time user event data and process it individually or combined with historical data to produce more accurate and relevant recommendations. Unlike historical data, new recorded data is used automatically when getting recommendations. Minimum requirements for new user data are:
- 1,000 records of combined interaction data
- 25 unique users with a minimum of 2 interactions each
References
Amazon Personalize is a fully managed machine learning service that goes beyond rigid static rule based recommendation systems and trains, tunes, and deploys custom ML models to deliver highly customized recommendations to customers across industries such as retail and media and entertainment.
It covers 6 use-cases:
Popular Use-cases
Following are the hands-on tutorials:
- Data Science on AWS Workshop - Personalize Recommendationsp
- https://aws.amazon.com/blogs/machine-learning/creating-a-recommendation-engine-using-amazon-personalize/
- https://aws.amazon.com/blogs/machine-learning/omnichannel-personalization-with-amazon-personalize/
- https://aws.amazon.com/blogs/machine-learning/using-a-b-testing-to-measure-the-efficacy-of-recommendations-generated-by-amazon-personalize/
Also checkout these resources: