Data Science
Data science is used in a variety of ways. Some data scientists focus on the analytics side of things, pulling out hidden patterns and insights from data, then communicating these results with visualizations and statistics. Others work on creating predictive models in order to predict future events, such as predicting whether someone will put solar panels on their house. Yet others work on models for classification; for example, classifying the make and model of a car in an image. One thing ties all applications of data science together: the data. Anywhere you have enough data, you can use data science to accomplish things that seem like magic to the casual observer.
The data science origin story
There's a saying in the data science community that's been around for a while, and it goes: "A data scientist is better than any computer scientist at statistics, and better than any statistician at computer programming." This encapsulates the general skills of most data scientists, as well as the history of the field.
Data science combines computer programming with statistics, and some even call data science applied statistics. Conversely, some statisticians think data science is only statistics. So, while we might say data science dates back to the roots of statistics in the 19th century, the roots of modern data science actually begin around the year 2000. At this time, the internet was beginning to bloom, and with it, the advent of big data. The amount of data generated from the web resulted in the new field of data science being born.
A brief timeline of key historical data science events is as follows:
- 1962: John Tukey writes The Future of Data Analysis, where he envisions a new field for learning insights from data
- 1977: Tukey publishes the book Exploratory Data Analysis, which is a key part of data science today
- 1991: Guido Van Rossum publishes the Python programming language online for the first time, which goes on to become the top data science language used at the time of writing
- 1993: The R programming language is publicly released, which goes on to become the second most-used data science general-purpose language
- 1996: The International Federation of Classification Societies holds a conference titled "Data Science, Classification and Related Methods" – possibly the first time "data science" was used to refer to something similar to modern data science
- 1997: Jeff Wu proposes renaming statistics "data science" in an inauguration lecture at the University of Michigan
- 2001: William Cleveland publishes a paper describing a new field, "data science," which expands on data analysis
- 2008: Jeff Hammerbacher and DJ Patil use the term "data scientist" in job postings after trying to come up with a good job title for their work
- 2010: Kaggle.com launches as an online data science community and data science competition website
- 2010s: Universities begin offering masters and bachelor's degrees in data science; data science job postings explode to new heights year after year; big breakthroughs are made in deep learning; the number of data science software libraries and publications burgeons.
- 2012: Harvard Business Review publishes the notorious article entitled Data Scientist: The Sexiest Job of the 21st Century, which adds fuel to the data science fire.
- 2015: DJ Patil becomes the chief data scientist of the US for two years.
- 2015: TensorFlow (a deep learning and machine learning library) is released.
- 2018: Google releases cloud AutoML, democratizing a new automatic technique for machine learning and data science.
- 2020: Amazon SageMaker Studio is released, which is a cloud tool for building, training, deploying, and analyzing machine learning models.
Frameworks
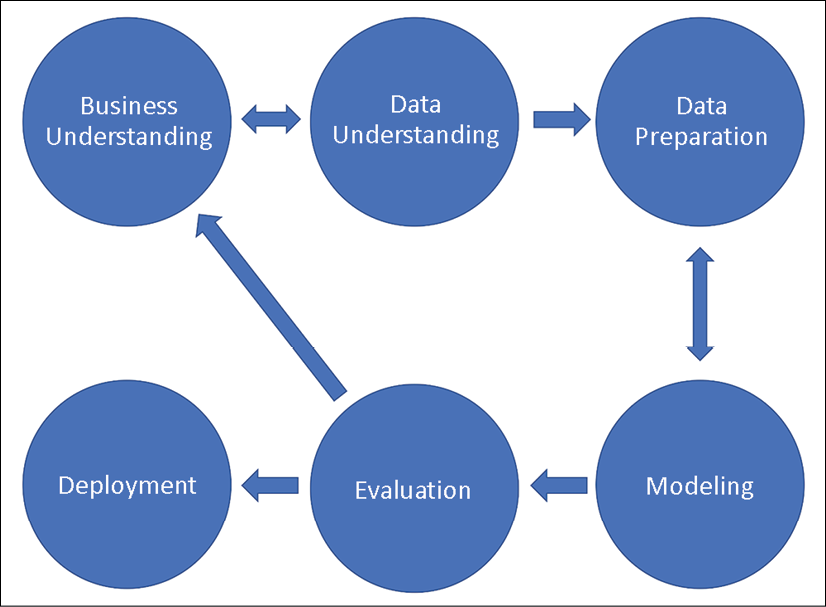
CRISP-DM
CRISP-DM stands for Cross-Industry Standard Process for Data Mining and has been around since the late 1990s. It's a six-step process, illustrated in the diagram below.
TDSP
TDSP, or the Team Data Science Process, was developed by Microsoft and launched in 2016. It's obviously much more modern than CRISP-DM, and so is almost certainly a better choice for running a data science project today.
The five steps of the process are similar to CRISP-DM, as shown in the figure below.
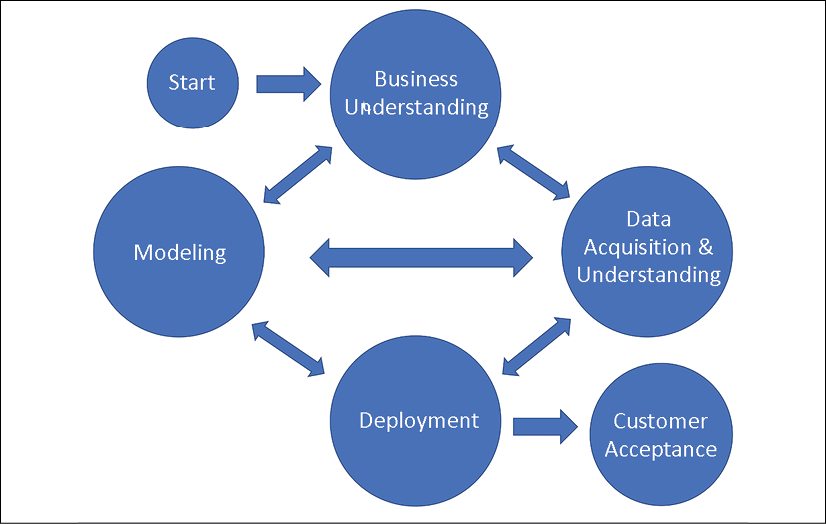
A reproduction of the TDSP process flow diagram.
Although the life cycle graphic looks quite different, TDSP’s project lifecycle is like CRISP-DM and includes five iterative stages:
- Business Understanding: define objectives and identify data sources
- Data Acquisition and Understanding: ingest data and determine if it can answer the presenting question (effectively combines Data Understanding and Data Cleaning from CRISP-DM)
- Modeling: feature engineering and model training (combines Modeling and Evaluation)
- Deployment: deploy into a production environment
- Customer Acceptance: customer validation if the system meets business needs (a phase not explicitly covered by CRISP-DM)