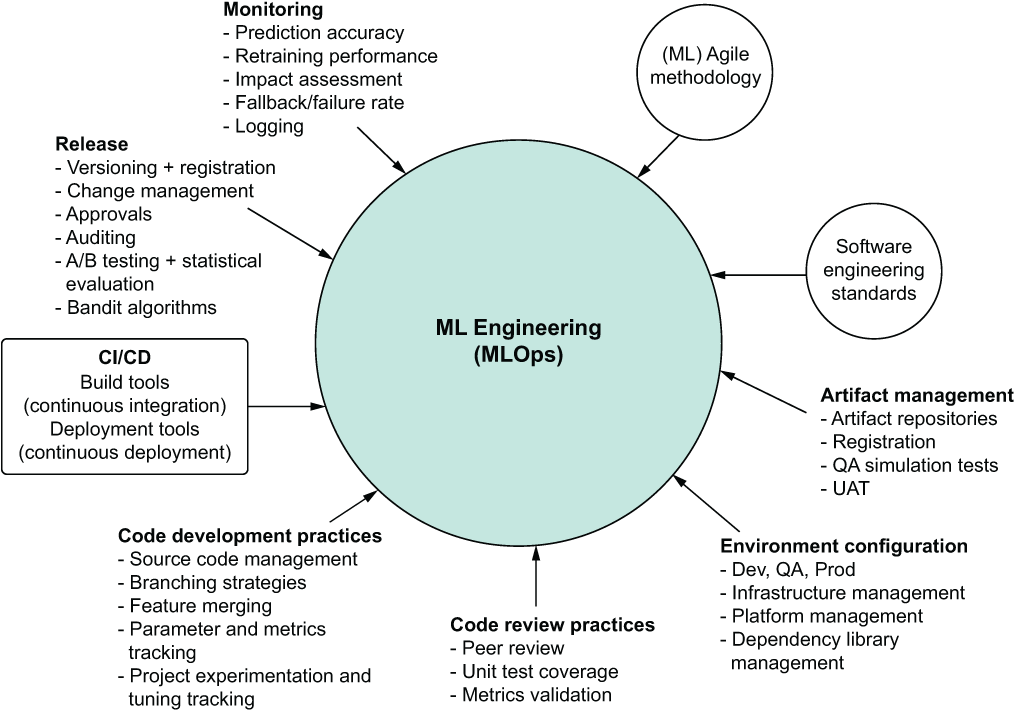
MLOps
The boom in AI has seen a rising demand for better AI infrastructure — both in the compute hardware layer and AI framework optimizations that make optimal use of accelerated compute. Unfortunately, organizations often overlook the critical importance of a middle tier: infrastructure software that standardizes the ML life cycle, adding a common platform for teams of data scientists and researchers to standardize their approach and eliminate distracting DevOps work. This process of building the ML life cycle is increasingly known as MLOps, with end-to-end platforms being built to automate and standardize repeatable manual processes. Although dozens of MLOps platforms exist, adopting one can be confusing and cumbersome. What should be considered when employing MLOps? What are the core pillars to MLOps, and which features are most critical?
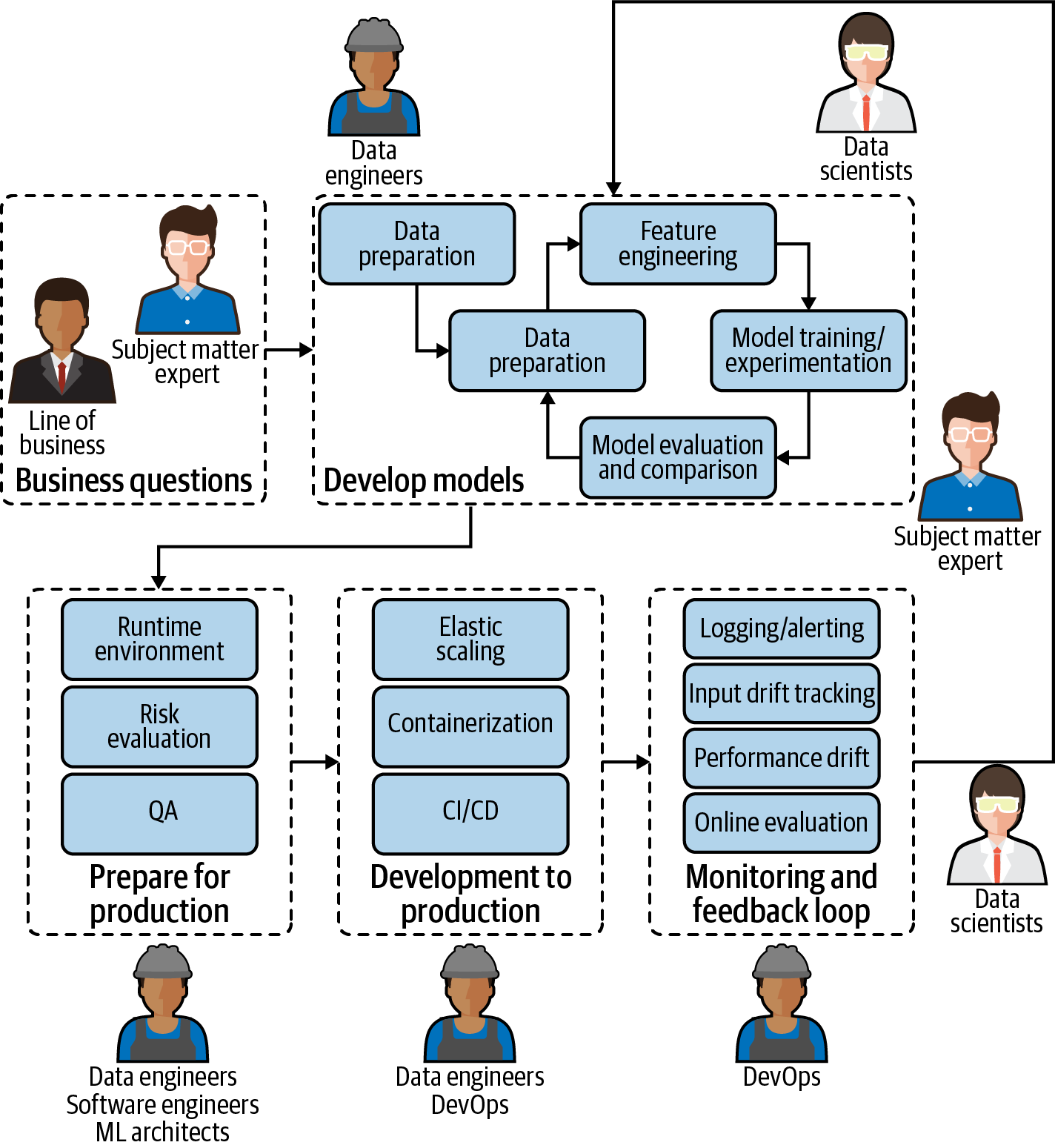
Getting your models into production is the fundamental challenge of machine learning. MLOps offers a set of proven principles aimed at solving this problem in a reliable and automated way. The faster you deliver a machine learning system that works, the faster you can focus on the business problems you're trying to crack. The following diagram is a realistic picture of an ML model life cycle inside an average organization today, which involves many different people with completely different skill sets and who are often using entirely different tools.
MLOps Setups
Before we look at any specific MLOps setups, let’s first establish three different setups representing the various stages of automation: manual implementation, continuous model delivery, and continuous integration/continuous delivery of pipelines.
Manual implementation refers to a setup where there are no MLOps principles applied and everything is manually implemented. The steps discussed above in the creation of a machine learning model are all manually performed. Software engineering teams must manually integrate the models into the application, and operational teams must help ensure all functionality is preserved along with collecting data and performance metrics of the model.
Continuous model delivery is a good middle ground between a manual setup and a fully automated one. Here, we see the emergence of pipelines to allow for automation of the machine learning side of the process. Note that we will mention this term quite often in the sections below. If you’d like to get a better idea about what a pipeline is, refer to the section titled “Pipelines and Automation” further down in this chapter. For now, a pipeline is an infrastructure that contains a sequence of components manipulating information as it passes through the pipeline. The function of the pipeline can slightly differ within the setups, so be sure to refer to the graphs and explanations to get a better idea of how the pipeline in the example functions.
The main feature of this type of setup is that the deployed model has pipelines established to continuously train it on new data, even after deployment. Automation of the experimental stage, or the model development stage, also emerges along with modularization of code to allow for further automation in the subsequent steps. In this setup, continuous delivery refers to expedited development and deployment of new machine learning models. With the barriers to rapid deployment lifted (the tediousness of manual work in the experimental stage) by automation, models can now be created or updated at a much faster pace.
Continuous integration/continuous delivery of pipelines refers to a setup where pipelines in the experimental stage are thoroughly tested in an automated process to make sure all components work as intended. From there, pipelines are packaged and deployed, where deployment teams deploy the pipeline to a test environment, handle additional testing to ensure both compatibility and functionality, and then deploy it to the production environment. In this setup, pipelines can now be created and deployed at a quick pace, allowing for teams to continuously create new pipelines built around the latest in machine learning architectures without any of the resource barriers associated with manual testing and integration.
Manual Implementation
In this case, there is a team of data scientists and machine learning engineers, who will now be referred to as the “model development team,” manually performing data analysis and building, training, testing, and validating their models. Once their model has been finalized, they must create a model class and push this to a code repository. Software engineers extract this model class and integrate it into an existing application or system, and operational teams are in charge of monitoring the application, maintaining functionality, and providing feedback to both the software and model development teams.
Everything here is manual, meaning any new trends in the data lead to the model development team having to update the model and repeat the entire process again. This is quite likely to happen considering the high volume of users interacting with your model every day. Combined with performance metrics and user data collection, the information will reveal a lot of aspects about your model as well as the user base the model is servicing. Chances are high that you will have to update it to maintain its performance on the new data. This is something to keep in mind as you follow through with the process on the graph.
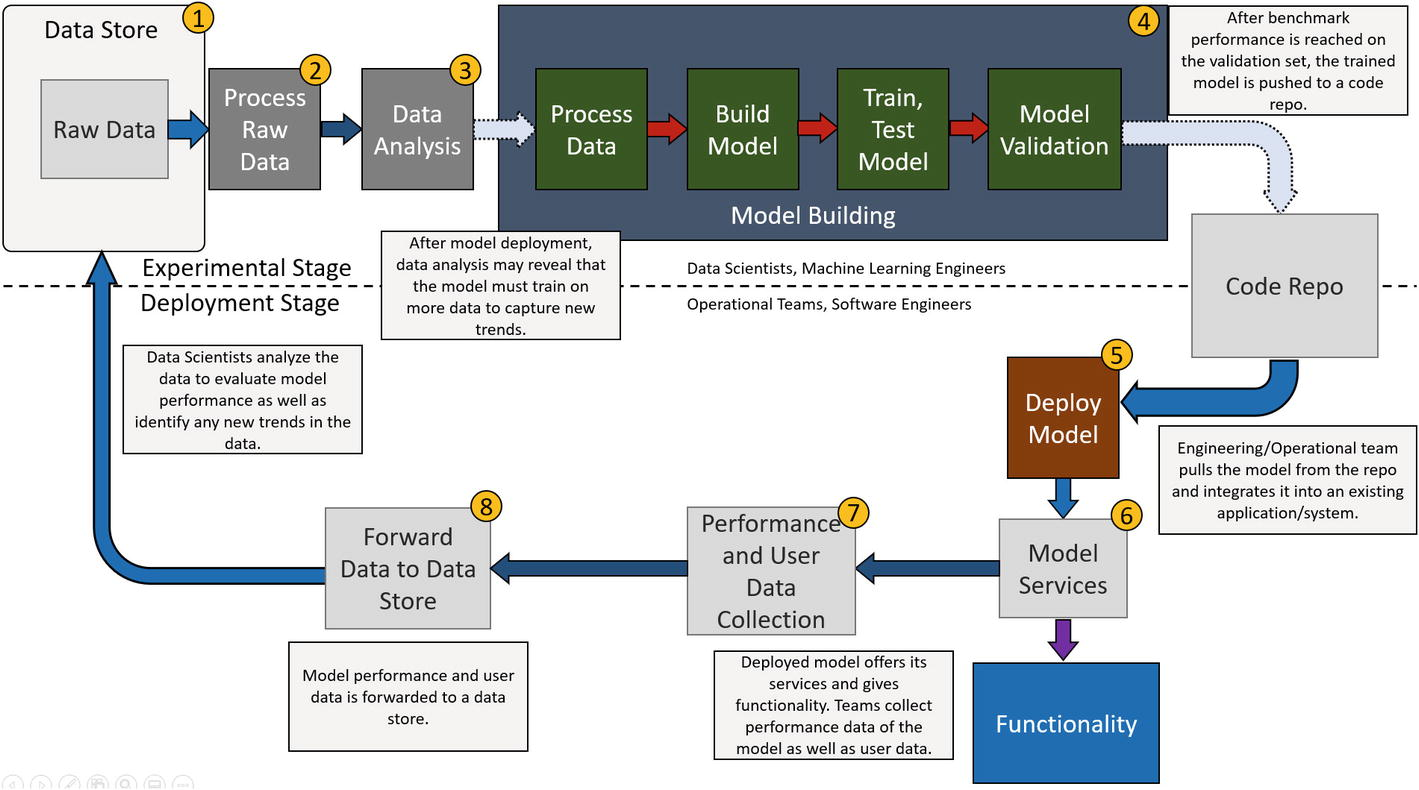
Let’s go through this step by step. We can split the flow into roughly two parts: the experimental stage , which involves the machine learning side of the entire workflow, and the deployment stage , which handles integration of the model into the application and maintaining operations.
Experimental Stage
- Data store: The data store refers to wherever data relevant to data analysis and model development is stored. An example of a data store could be using Hadoop to store large volumes of data, which can be used by multiple model development teams. In this example, data scientists can pull raw data from this data store to start performing experiments and conducting data analysis.
- Process raw data: As previously mentioned, raw data must be processed in order to collect the relevant information. From there, it must also be purged of faults and corrupted data. When a company collects massive volumes of data every day, some of it is bound to be corrupted or faulty in some way eventually, and it’s important to get rid of these points because they can harm the data analysis and model development processes. For example, one null value entry can completely destroy the training process of a neural network used for a regression (value prediction) task.
- Data analysis: This step involves analyzing all aspects of the data. The general gist of it was discussed earlier, but in the context of updating the model, data scientists want to see if there are any new trends or variety in data that they think the model should be updated on. Since the initial training process can be thought of as a small representation of the real-world setting, there is a fair chance that the model will need to be updated soon after the initial deployment. This does depend on how many characteristics of the true user base the original training set captured however, but user bases change over time, and so must the models. By “user base,” we refer to the actual customers using the prediction services of the model.
- Model building stage: This stage is more or less the same as what we discussed earlier. The second time around, when updating the model, it could turn out that slight adjustments to the model layers may be needed. In some of the worst cases, the current model architecture being used cannot achieve a high enough performance even with new data or architectural tweaks. An entirely new model may have to be built, trained, and validated. If there are no such issues, then the model would just be further trained, tested, validated, and pushed to the code repository upon meeting some performance criteria.
An important thing to note about this experimental stage is that it is quite popular for experiments to be conducted using Jupyter notebook. When model development teams reach a target level of performance, they must work on building a workable model that can be called by other code. For example, this can be done by creating a model class with various functions that provide functionality such as load_weights, predict, and perhaps even evaluate to allow for easier gathering of performance metrics. Since the true label can’t be known in real-time settings, evaluation metrics can simply be something like a root-mean-squared error.
Deployment Stage:
Model deployment: In this case, this step is where software engineers must manually integrate the model into the system/application they are developing. Whenever the model development team finishes with their experiments, builds a workable model, and pushes it to the code repository, the engineering team must manually integrate it again. Although the process may not be that bad the second time around, there is still the issue of fixing any potential bugs that may arise from the new model. Additionally, engineering teams must also handle testing of not only the model once it is integrated into the application, but also of the rest of the application.
Model services: This step is where the model is finally deployed and is interacting with the user base in real time. This is also where the operational team steps in to help maintain the functionality of the software. For example, if there are any issues with some aspect of the model functionality, the operational team must record the bug and forward it to the model development team.
Data collection: The operational team can also collect raw data and performance metrics. This data is crucial for the company to operate since that is how it makes its decisions. For example, the company might want to know what service is most popular with the user base, or how well the machine learning models are performing so far. This job can be performed by the application as well, storing all the relevant data in some specific data store related to the application.
Data forwarded to data store: This step is where the operational team sends the data to the data store. Because there could be massive volumes of data collected, it’s fair to assume some degree of automation on behalf of the operational team on this end. Additionally, the application itself could also be in charge of forwarding data it collects to the relevant data store.
Reflection on the Setup
Right away, you can notice some problems that may arise from such an implementation. The first thing to realize is that the entire experimental stage is manual, meaning data scientists and machine learning engineers must repeat those steps every time. When models are constantly exposed to new data that is more than likely not captured in the original training set, models must frequently be retrained so that they are always up to date with current trends in user data. Unfortunately, when the entire process of analyzing new trends, training, testing, and validating data is manual, this may require significant resources over time, which may become unfeasible for a company without the resources to spare. Additionally, trends in data can change over time. For example, perhaps the age group with the largest number of users logging into the site is comprised of people in their early twenties. A year later, perhaps the dominant age group is now teenagers. What was normal back then isn’t normal now, and this could lead to losses in ad revenues, for example, if that’s the service (targeted advertising) the model in this case provides.
Another issue is that tools such as Jupyter notebook are very popular for prototyping and experimenting machine learning and deep learning models. Even if the experiments aren’t carried out on notebooks, it’s likely that work must be done in order to push the model to the source repo. For example, constructing a model class with some important functions such as load_weights, predict, and evaluate would be ideal for a model class. Some external code may call upon load_weights() to set the model weights from different training instances (so if the model has been further trained and updated, simply call this function to get the new model). The function predict() would then be called to make predictions based on some input data and provide the services the application requires, and the function evaluate() would be useful in keeping performance metrics. Live data will almost never have truth labels on it (unless the user provides instant feedback, like Google’s captchas where you select the correct images), so a score metric like a root-mean-squared error can be useful when keeping track of performance.
Once the model class is completed and pushed, software engineering teams must integrate the model class into the overall application/system. This could prove difficult the first time around, but once the integration has been completed, updates to the model can be as simple as loading new weights. Unfortunately, model architectures are likely to change, so the software teams must reintegrate new model classes into the application.
Furthermore, deep learning is a complicated and rapidly evolving field. Models that were cutting-edge several years ago can be far surpassed by the current state-of-the-art models, so it’s important to keep updating your model architectures and to make full use of the new developments in the field. This means teams must continuously repeat the model-building process in order to keep up with developments in the field.
Hopefully it is more clear that this implementation is quite flawed in how much work is required to not only create and deploy the model in the first place, but also to continuously maintain it and keep it up to par.
Continuous Model Delivery
This setup contains pipelines for automatic training of the deployed model as well as for speeding up the experimental process.
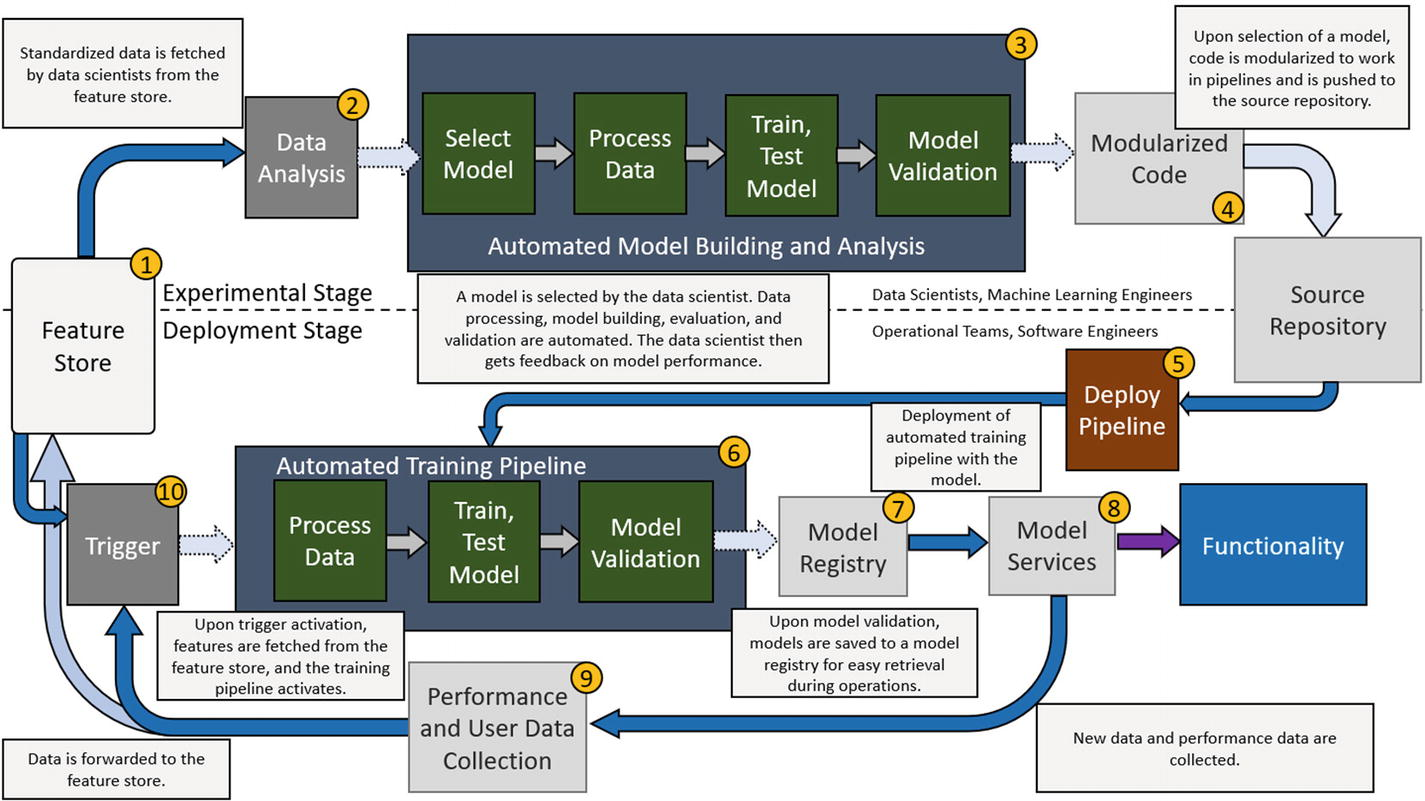
This is a lot to take in at once, so let’s break it down and follow it according to the numbers on the graph.
- Feature store: This is a data storage bin that takes the place of the data store in the previous example. The reason for this is that all data can now be standardized to a common definition that all processes can use in this instance. For example, the processes in the experimental stage will be using the same input data as the deployed training pipeline because all of the data is held to the same definition. What is meant by common definition is that raw data is cleansed and processed in a procedural way that applies to all relevant raw data. These processed features are then held in the feature store for pipelines to draw from, and it is ensured that every pipeline uses features processed according to this standard. This way, any perceived differences in trends between two different pipelines won’t be attributed to deviances in processing procedures. Presume for an instance that you are trying to provide an object detection service that detects and identifies various animals in a national park. All video feed from the trail cameras (a video can be thought of as a sequence of frames) can be stored as raw data, but it can be possible that different trail cameras have different resolutions. Instead of repeating the same data processing procedure, you can simply apply the same procedure (normalizing, scaling, and batching the frames, for example) to the raw videos and store the features that you know all pipelines will use.
- Data analysis: In this step, data analysis is still performed to give data scientists and machine learning engineers an idea of what the data looks like, how it’s distributed, and so on, just like in the manual setup. Similarly, this step can determine whether or not to proceed with construction of a new model or just update the current model.
- Automated model building and analysis: In this step, data scientists and machine learning engineers can select a model, set any specific hyperparameters, and let the pipeline automate the entire process. The pipeline will automatically process the data according to the specifications of this model (take the case where the features are 331x331x3 images but this particular model only accepts images that are 224x224x3), build the model, train it, evaluate it, and validate it. During validation, the pipeline may automatically tune the hyperparameters as well optimize performance. It is possible that manual intervention may be required in some cases (debugging, for example, when the model is particularly large and complex, or if the model has a novel architecture), but automation should otherwise take care of producing an optimal model. Once this occurs, modularized code is automatically created so that this pipeline can be easily deployed. Everything in this stage is set up so that the experimental stage goes very smoothly, requiring only that the model is built. Depending on the level of automation implemented, perhaps all that is required is that the model architecture is selected with some hyperparameters specified, and the automation takes care of the rest. Either way, the development process in the experimental stage is sped up massively. With this stage going faster, more experiments can be performed too, leading to possible boosts in overall efficiency as productivity is increased and optimal solutions can be found quicker.
- Modularized code: The experimental stage is set up so that the pipeline and its components are modularized. In this specific context, the data scientist/machine learning engineer defines and builds some model, and the data is standardized to some definition. Basically, the pipeline should be able to accept any constructed model and perform the corresponding steps given some data without hardcoding anything. (Meaning there isn’t any code that will only work for a specific model and specific data. The code works with generalized cases of models and data.) This is modularization , when the whole system is divided into individual components that each have their own function, and these components can be switched out depending on variable inputs. Thanks to the modularized code, when the pipeline is deployed, it will be able to accept any new feature data as needed in order to update the deployed model. Furthermore, this structure also lets it swap out models as needed, so there’s no need to construct the entire pipeline for every new model architecture. Think of it this way: the pipeline is a puzzle piece, and the models along with their feature data are various puzzle pieces that can all fit within the pipeline. They all have their own “image” on the piece and the other sides can have variable shapes, but what is important is that they fit with the pipeline and can easily be swapped out for others.
- Deploy pipeline: In this step, the pipeline is manually deployed and is retrieved from the source code. Thanks to its modularization, the pipeline setup is able to operate independently and automatically train the deployed model on any new data if needed, and the application is built around the code structure of the pipeline so all components will work with each other correspondingly. The engineering team has to build parts of the application around the pipeline and its modularized components the first time around, but after that, the pipelines should work seamlessly with the applications so as long as the structure remains the same. Models are simply swapped, unlike before when the model had to be manually integrated into the application. This time, the pipeline must be integrated into the application, and the models are simply swapped out. However, it is important to mention that pipeline structures can change depending on the model. The main takeaway here is that pipelines should be able to handle many more models before having to be restructured compared to the setup before where “swapping” models meant you only loaded updated weights. Now, if several architectures all have common training, testing, and validation code, they can all be used under the same pipeline.
- Automated training pipeline: This pipeline contains the model that provides its services and is set up to automatically fetch new features upon activation of the trigger. The conditions for trigger activation will be discussed in item 10. When the pipeline finishes updating a trained model, the model is saved to a model registry, a type of storage unit that holds trained models for ease of access.
- Model registry: This is a storage unit that specifically holds model classes and/or weights. The purpose of this unit is to hold trained models for easy retrieval by an application, for example, and it is a good component to add to an automation setup. Without the model registry, the model classes and weights would just be saved to whatever source code repository is established, but this way, we make the process simpler by providing a centralized area of storage for these models. It also serves to bridge the gap between model development teams, software development teams, and operational teams since it is accessible by everyone, which is ultimately what we want in an ideal automation setup. This registry along with the automated training pipeline assures continuous delivery of model services since models can frequently be updated, pushed to this registry, and deployed without having to go through the entire experimental stage.
- Model services: Here the application pulls the latest, best performing model from the model registry and makes use of its prediction services. This action then goes on to provide the desired functionality in the application.
- Performance and user data collection: New data is collected as usual along with performance metrics related to the model. This data goes to the feature store, where the new data is processed and standardized so that it can be used in both the experimental stage and the deployment stage and there are no discrepancies between the data used by either stage. Performance data is stored so that data scientists can tell how the model is performing once deployed. Based on that data, important decisions such as whether or not to build a new model with a new architecture can be made.
- Training pipeline trigger: This trigger, upon activation, initiates the automated training pipeline for the deployed model and allows for feature retrieval by the pipeline from the feature store. The trigger can have any of the following conditions, although it is not limited to them:
- Manual trigger: Perhaps the model is to be trained only if the process is manually initiated. For example, data science teams can choose to start this process after reviewing performance and data and concluding that the deployed model needs to train on fresh batches of data.
- Scheduled training: Perhaps the model is set to train on a specific schedule. This can be a certain time on the weekend, every night during hours of lowest traffic, every month, and so on.
- Performance issues: Perhaps performance data indicates that the model’s performance has dipped below a certain benchmark. This can automatically activate the training process to attempt to get the performance back up to par. If this is not possible or is taking too many resources, data scientists and machine learning engineers can choose to build and deploy a new model.
- Changes in data patterns: Perhaps changes in the trends of the data have been noticed while creating the features in the feature store. Of course, the feature store isn’t the only possible place that can analyze data and identify any new trends or changes in the data. There can be a separate process/program dedicated to this task, which can decide whether or not to activate the trigger. This would also be a good condition to begin the training process, since the new trends in the data are likely to lead to performance degradation. Instead of waiting for the performance hit to activate the trigger, the model can begin training on new data immediately upon sufficient detection of such changes in the data, allowing for the company to minimize any potential losses from such a scenario.
Reflection on the Setup
This implementation fixes many of the issues from the previous setup. Thanks to the integration of pipelines in the experimental stage, the previous problem of having the entire stage be composed of manual processes is no longer a concern. The pipeline automates the whole process of training, evaluating, and validating a model. The model development team now only needs to build the model and reuse any common training, evaluation, and validation procedures that are still applicable to this model. At the end of the model development pipeline, relevant model metrics are collected and displayed to the operator. These metrics can help the model development team to prototype quickly and arrive at optimal solutions even faster than they would have without the automation since they can run multiple pipelines on different models and compare all of them at once.
Automated model creation pipelines in the experimental stage allow for teams to respond faster to any significant changes in the data or any issues with the deployed model that need to be resolved. Unlike before, where the only model swapping was the result of loading updated weights for the same model, these pipelines are structured to allow for various models with different architectures as long as they all use the same training, evaluation, and validation procedures. Thanks to the modularized code, the pipeline can simply swap out model classes and their respective weights once deployed. The modularization allows for easier deployment of the pipeline and lets models be swapped out easily to allow for further training of any model during deployment. Should a model require special attention from the model development team, it can simply be trained further by the team and swapped back in once it is ready. Now teams can respond much more quickly by being able to swap models in and out in such a manner.
The pipelines also make it much easier for software engineering teams and operational teams to deploy the pipelines and models. Because everything is modularized, teams do not have to work on integrating new model classes into the application every time. Everyone benefits, and model development teams do not have to be as hesitant about implementing new architectures so as long as the new model still uses the same training, evaluation, and validation code as in the existing pipeline.
While this setup solves most of the issues that plagued the original setup, there are still some important problems that remain. Firstly, there are no mechanisms in place to test and debug the pipelines, so this must all be done manually before it is pushed to a source repository. This can become a problem when you’re trying to push many iterations of pipelines, such as when you’re building different models with architectures that differ in how they must be trained, tested, and validated. Perhaps the latest models are showing a vast improvement over the old state-of-the art, and your team wants to implement these new solutions as soon as possible. In situations like this, teams will frequently need to debug and test pipelines before pushing them to source code for deployment. In this case, there is still some automation left to be done to avoid manual work.
Pipelines are also manually deployed, so if the structure in the code changes, the engineering teams must rebuild parts of the application to work with the new pipeline and its modularized code. Modularization works smoothly when all components know what to expect from each other, but if the code of one of the components changes so that it isn’t compatible anymore, either the application must be rebuilt to accommodate the new changes or the component must be rewritten to work with the original pipeline. Unfortunately, new model architectures may require that part of the pipeline itself be rewritten, so it is likely that the application itself must be worked on to accommodate the new pipeline.
Hopefully you begin to see the vast improvements that automation has made in this setup, but also the issues that remain to be solved. The automation has solved the issue of building and creating new models, but the problem of building and creating new pipelines still remains.
Continuous Integration/continuous delivery of pipelines
In this setup, we will be introducing a system to thoroughly test pipeline components before they are packaged and ready to deploy. This will ensure continuous integration of pipeline code along with continuous delivery of pipelines, crucial elements of the automation process that the previous setup was missing.
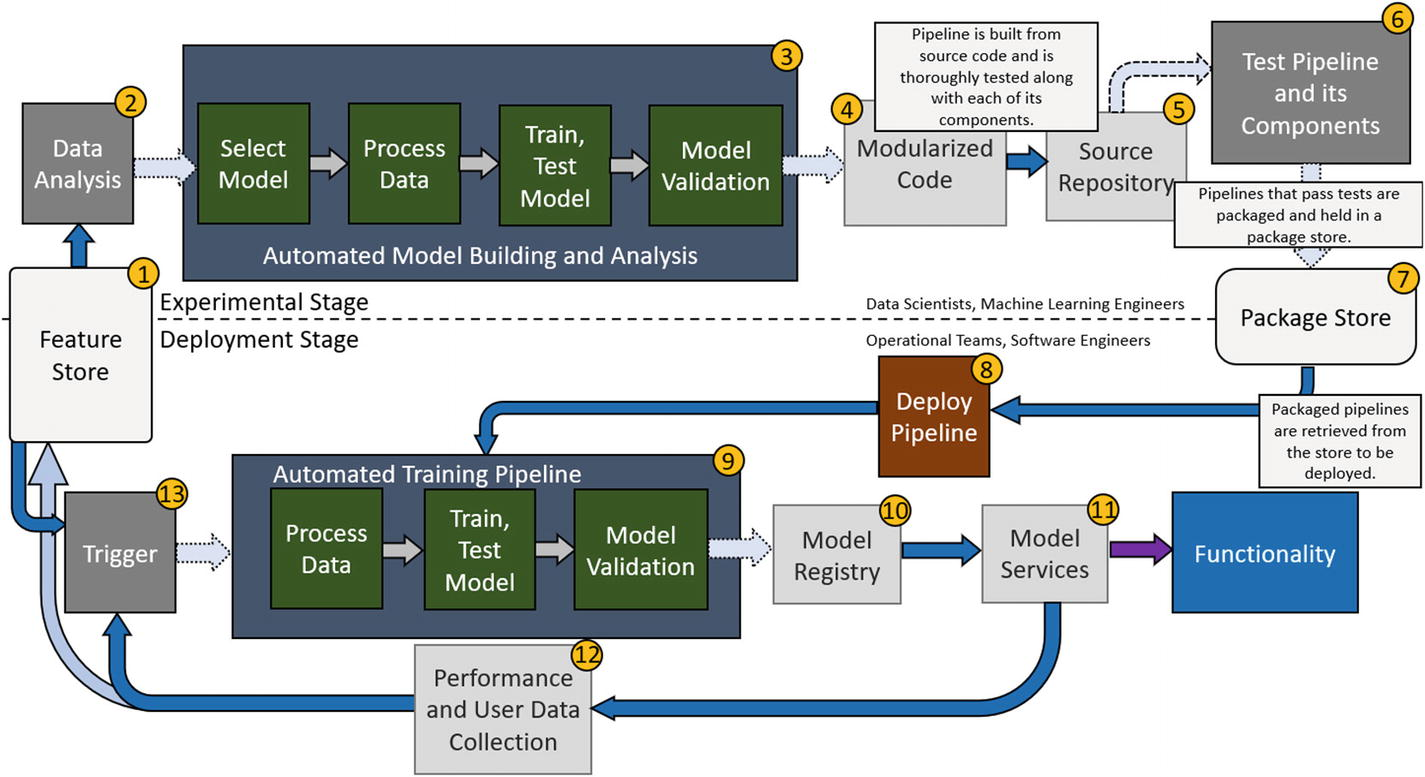
Though this is mostly the same setup, we will go through it again step by step with an emphasis on the newly introduced elements.
- Feature store: The feature store contains standardized data processed into features. Features can be pulled by data scientists for offline data analysis. Upon activation of the trigger, features can also be sent to the automated training pipeline to further train the deployed model.
- Data analysis: This step is performed by data scientists on features pulled from the feature store. The results from the analysis can determine whether or not to build a new model or adjust the architecture of an existing model and retrain it from there.
- Automated model building and analysis: This step is performed by the model development team. Models can be built by the team and passed into the pipeline, assuming that they are compatible with the training, testing, and validation code, and the entire process is automatically conducted with a model analysis report generated at the end. In the case where the team wants to implement some of the latest machine learning architectures, models will have to be created from scratch with integration into pipelines in mind to maintain modularity. Parts of the pipeline code may have to change as well, which is acceptable because the new components of this setup can handle this automatically.
- Modularized code: Once the model reaches a minimum level of performance in the validation step, the pipeline, its components, and the model are all ready to be modularized and stored in a source repository.
- Source repository: The source repository holds all of the packaged pipeline and model code for different pipelines and different models. Teams can create multiples at once for different purposes and store them all here. In the old setup, pipelines and models would be pulled from here and manually integrated and deployed by software engineering teams. In this setup, the modularized code must now be tested to make sure all of the components will work correctly.
- Testing: This step is crucial in achieving continuous integration, or a result of automation where new components and elements are continuously designed, built, and deployed in the new environment.
Pipelines and their components, including the model, must be thoroughly tested to ensure that all outputs are correct. Furthermore, the pipelines themselves must be tested so that they are guaranteed to work with the application and how it is designed. There shouldn’t be bugs in the pipeline, for example, that would break its compatibility with the application. The application is programmed to expect a specific behavior from the pipeline, and the pipeline must behave correspondingly.
If you are familiar with software development, the testing of pipeline components and the models is similar to the automated testing that developers write to check various parts of an application’s functionality. A simple example is automated testing to ensure data of various types are successfully received by the server and are added to the correct databases.With pipelines and machine learning models, some examples of testing include:
1. Does the validation testing procedure lead to correct tuning of the hyperparameters?
2. Does each pipeline component work correctly? Does it output the expected element? For example, after model evaluation, does it correctly begin the validation step? (Alternatively, if model evaluation goes after model validation, does the evaluation step correctly initiate?)
3. Is the data processing performed correctly? Are there any issues with the data post-processing that would lead to poor model performance? Avoiding this outcome is for the best since it would waste resources having to fix the data processing component. If the business relies on rapid pipeline deployment, then avoiding this type of scenario is even more crucial.
4. Does the data processing component correctly perform data scaling? Does it correctly perform feature engineering? Does it correctly transform images?
5. Does the model analysis work correctly? You want to make sure that you’re basing decisions on accurate data. If the model truly performs well but faults in the model analysis component of the pipeline lead the data scientist/machine learning engineer to believe the model isn’t performing that well, then it could lead to issues where pipeline deployment is slowed down. Likewise, you don’t want the model analysis to be displaying the wrong information, even if it mistakenly displays precision for accuracy.
The more thorough the automated testing, the better the guarantee that the pipeline will operate within the application without issues. (This doesn’t necessarily include model performance as that has to do more with the model architecture, how the model is developed, and what it is capable of.)
Once the pipeline passes all the tests, it is then automatically packaged and sent to a package store. Continuous integration of pipelines is now achieved since teams can build modularized and tested pipelines much more quickly and have them ready for deployment. - Package store: The package store is a containment unit that holds various packaged pipelines. It is optional but included in this setup so that there is a centralized area where all teams can access packaged pipelines that are ready for deployment. Model development teams push to this package store, and software engineers and operational teams can retrieve a packaged pipeline and deploy it. In this way, it is similar to the model registry in that both help achieve continuous delivery. The package store helps achieve continuous delivery of pipelines just as the model registry helps achieve continuous delivery of models and model services. Thanks to automated testing providing continuous integration of pipelines and continuous delivery of pipelines via the package store, pipelines can also be deployed rapidly by operational teams and software engineers. With this, businesses can easily keep up with the latest trends and advances in machine learning architectures, allowing for better and better performance and more involved services.
- Deploy pipeline: Pipelines can be retrieved from the package store and deployed in this step. Software engineering and operational teams must ensure that the pipeline will integrate without incident into the application. Because of that, there can be more testing on the part of software engineering teams to ensure proper integration of the pipeline. For example, one test can be to ensure the dependencies of the pipeline are considered in the application (if, for example, TensorFlow has updated and contains new functionality the pipeline now uses, the application should update its version of TensorFlow as well). Teams usually want to deploy the pipelines into a test environment where it will be subjected to further automated testing to ensure full compatibility with the application. This can be done automatically, where the pipelines go from the package store into the test environment, or manually, where teams decide to deploy the pipeline into the test environment. After the pipeline passes all the tests, teams can choose to manually deploy the pipeline into the production environment or have it automatically done. Either way, pipeline creation and deployment is a much faster process now especially since teams do not have to manually test the pipelines and they do not have to build or modify the application to work with the pipeline every time.
- Automated training pipeline: The automated training pipeline, once deployed, exists to further train models upon activation of the trigger. This helps keep models as up to date as possible on new trends in data and maintain high performance for longer. Upon validation of the model, models are sent to the model registry where they are held until they are needed for services.
- Model registry: The model registry holds trained models until they are needed for their services. Once again, continuous delivery of model services is achieved as the automated training pipeline continuously provides the model registry with high-performance machine learning models to be used to perform various services.
- Model services: The best models are pulled from the model registry to perform various services for the application.
- Performance and user data collection: Model performance data and user data is collected to be sent to model development teams and the feature store, respectively. Teams can use the model performance metrics along with the results from the data analysis to help decide their next course of action.
- Training pipeline trigger: This step involves some condition being met (refer to the previous setup, continuous model delivery) to initiate the training process of the deployed pipeline and feed it with new feature data pulled from the feature store.
Reflection on the Setup
The main issue of the previous setup that this one fixes is that of pipeline deployment. Previously, pipelines had to be manually tested by machine learning teams and operational teams to ensure that the pipeline and its components worked, and that the pipeline and its components were compatible with the application. However, in this setup, testing is automated, allowing for teams to much more easily build and deploy pipelines than before. The biggest advantage to this is that businesses can now keep up with significant changes in the data requiring the creation of new models and new pipelines, and can also capitalize on the latest machine learning trends and architectures all thanks to rapid pipeline creation and deployment combined with continuous delivery of model services from the previous setup.
The important thing to understand from all these examples is that automation is the way to go. Machine learning technology has progressed incredibly far within the last decade alone, but finally, the infrastructure to allow you to capitalize on these advancements is catching up.
Hopefully, after seeing the three possible MLOps setups, you understand more about MLOps and how implementations of MLOps principles might look. You might have noticed that pipelines have been mentioned quite often throughout the descriptions of the setups, and you might be wondering, “What are pipelines, and why are they so crucial for automation?”
Extended MLOps
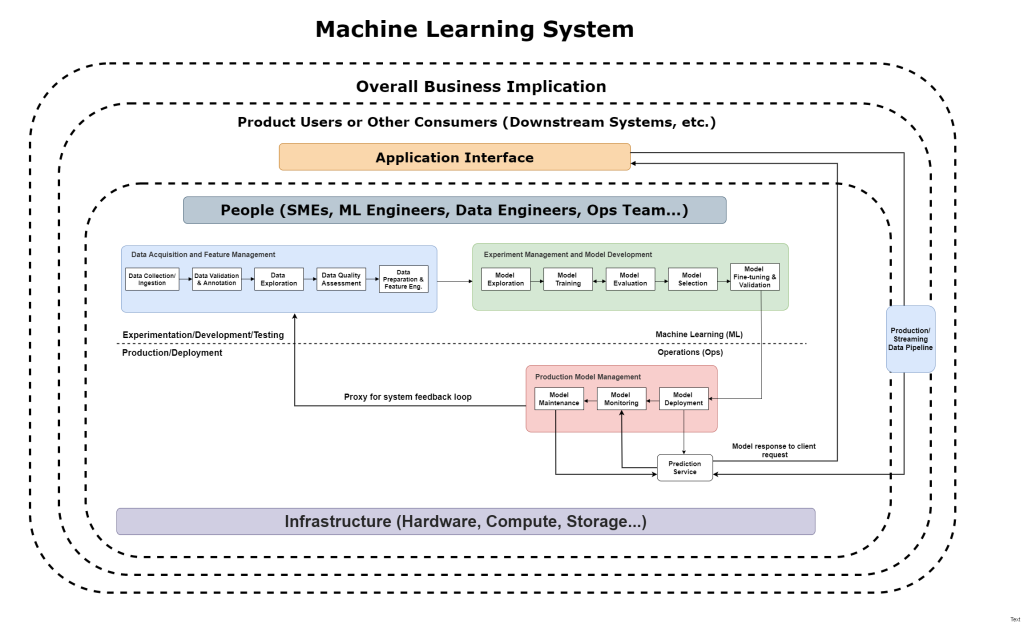
Pipelines and Automation
Pipelines are an important part of automation setups employing DevOps principles. One way to think about a pipeline is that it is a specific, often sequential procedure that dictates the flow of information as it passes through the pipeline.
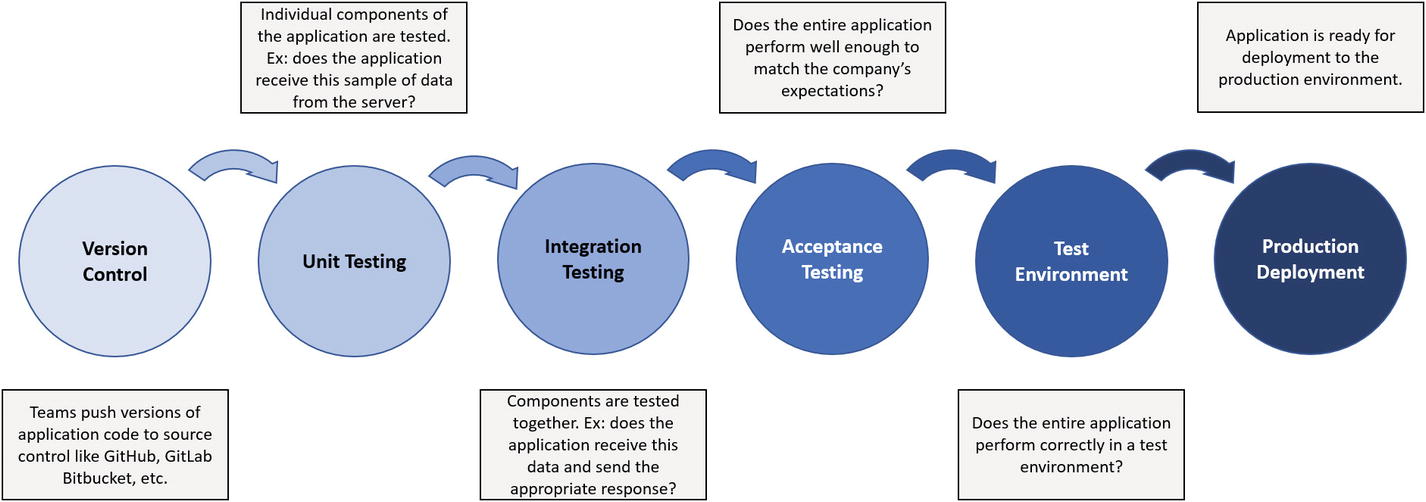
A testing pipeline in a software development setting. The pipeline for testing packaged model pipelines in the optimal setup above is similar in that individual components must be tested, components must be tested in groups, and in the case where pipelines are deployed to a test environment first where further tests are performed before they are deployed to the production environment
In the MLOps setups above, you’ve seen pipelines for automating the process of training a deployed model and for building, testing, and packing pipelines as well as for testing integration of packaged pipelines before deploying them to the production environment.
So, what does all that really mean? To get a better idea of what exactly goes on in a pipeline, let’s follow the flow of data through a pipeline in the experimental stage. Even if you understand how pipelines work, it may be worth following the example anyway as we now look at this pipeline through the context of using MLOps APIs.
JOURNEY THROUGH A PIPELINE
We will be looking at the model development pipeline in the experimental stage. Before we begin, it is important to mention that we will be referencing API calls in this pipeline. This is because some APIs can be called while executing scripts or even Jupyter cells at key points in the model’s development, giving MLOps monitoring software information on model training, model evaluation, and model validation. At the end of the pipeline, the MLOps software would also ready the model for deployment via functionality provided by the API.
You will read more about this API in the next chapter, Chapter 4, but for now, you may assume that the API will take care of automation as you follow along through the example.
Model Selection
As seen in Figure 3-4, the experimental pipeline begins with the selection of a model. This is up to the operator, who must now choose and build a model. Some APIs allow you to call their functionality while building the model to connect with MLOps software as the rest of the process goes on. This software then keeps track of all relevant metrics related to the model’s development along with the model itself in order to initiate the deployment process.
In this case, the operator has chosen to use a logistic regression. Refer to Figure 3-6.Figure 3-6 A graphical representation of a pipeline where the operator has selected a logistic regression model. The rest of the steps have been hidden for now and will appear as we gradually move through the pipeline

Data Preprocessing
With the model now selected and built, and with feature data supplied by the feature store, the process can now move forward to the next stage in the pipeline: data preprocessing. Refer to Figure 3-7.Figure 3-7 The operator has chosen to normalize and resize the image data. The process creates a training set, a testing set, and a validation set

The data preprocessing can be done manually or automatically. In this case, the data preprocessing only involves normalization and resizing of image feature data, so the operator can implement this manually. Depending on the level of automation, the operator can also call some function that takes in data and automatically processes it depending on the type of data and any other parameters provided.
Either way, the end of the processing stage will result in the data being broken up into subsets. In this example, the operator chose to create a training set, a testing set, and a validation set. Now, the operator can begin the training process.
Training Process
Depending on the framework being used, the operator can further split up the training data into a training set and a data validation set and use both in the training process. The data validation set exists totally separate from the training set (although it is derived from it) since the model never sees it during training. Its purpose is to periodically evaluate the model’s performance on a data set that it has never seen before. Refer to Figure 3-8.Figure 3-8 The model training process begins

In the context of deep learning, for example, the model can evaluate on the validation set at the end of each epoch, generating some metric data for the operator to see. Based on this, the operator can judge how the model is doing and whether or not it could be overfitting and adjust hyperparameters or model structure if needed.
The API can also be told what script to run in order to initiate this entire pipeline process. The script can contain the training, evaluation, and validation code all at once so the API can run this entire pipeline when needed.
Once the training process is done, the process moves to the evaluation stage.
Model Evaluation
In the evaluation stage, the model’s performance is measured on a test data set that it has never seen. This performance will indicate to the operator whether or not the model is overfitting, especially if it performed extremely well in training but has trouble replicating those results in this stage. That is part of why the training data can be split to include some validation data, as it can be an early indicator of overfitting. This can be crucial especially if the model takes a significant amount of time to run. You would rather know earlier, partway through training, if the model is overfitting, rather than after it ran all night and is evaluated the next morning. Refer to Figure 3-9.Figure 3-9 Training results are stored in a common area (for example, the API could be called to monitor these results) for the metrics of the current model. Model evaluation begins on the trained model using the testing set

Another thing to note again is that the validation stage could come before the evaluation stage, but in this case, the trained model will be evaluated first on a test data set before the validation stage begins. This is just to get a sense of how the model does on the testing set before hyperparameter tuning begins. Of course, hyperparameter tuning via the validation step could be performed first before the final model evaluation, but in some frameworks, model evaluation would come first. An example of this is a validation process like scikit-learn’s cross-validation. Of course, you can evaluate the tuned model on the test set once again to get a final performance evaluation.
Once the evaluation finishes, metrics are stored by the API or by some other mechanism that the team has implemented, and the process moves on to the validation stage.
Model Validation
In this stage, the model begins the validation process, which attempts to seek the best hyperparameters. You could combine the use of a script to iterate through various configurations of hyperparameter values and utilize k-fold cross-validation, for example, to help decide the best hyperparameters. Refer to Figure 3-10.Figure 3-10 Evaluation metrics are stored along with the training metrics by the API, and the validation process begins

In any case, the point of a validation set is to help tune the model’s hyperparameters. The team could even automate this process entirely if they tend to train a lot of models of the same few types, saving time and resources in the long run by automating the validation and hyperparameter tuning process for that set of models.
Finally, once the model achieves a good level of performance and finishes the validation stage, the validation results are stored, and all relevant data is displayed as a summary to the operator. Again, depending on the level of automation, perhaps the model is retrained and evaluated on the best hyperparameter setup discovered in the validation stage. The API simply needs to be told what metrics to track and it will automatically do so.
Model Summary
At this point, the operator can compare the outcome of this experiment with that of other models, using the metrics as baselines for comparison. The API can track the relevant metrics for different model runs and can compare them all at the same time. Should the operator decide to move forward with this particular model, the API and the MLOps software can allow for deployment on a simple click of a button. Usually, the deployment is to a staging environment first, where the functionality can be tested further before moving directly into the production environment. Everything is configurable, and the API can adapt to the needs of the business and its workflow. If the developers want to deploy straight to production, sure, though that could potentially be unwise considering the case of failure. Refer to Figure 3-11.Figure 3-11 Validation is complete, and all metrics are displayed to the operator

After the model passes the tests in the staging environment, it can then be deployed to the production environment, where it can be further monitored by the software.
Ben Wilson
Ben Wilson, the author of "Machine Learning Engineering", proposed: