Incremental Learning
Humans and animals have the ability to continually acquire, fine-tune, and transfer knowledge and skills throughout their lifespan. This ability, referred to as lifelong learning, is mediated by a rich set of neurocognitive mechanisms that together contribute to the development and specialization of our sensorimotor skills as well as to long-term memory consolidation and retrieval. Consequently, lifelong learning capabilities are crucial for autonomous agents interacting in the real world and processing continuous streams of information. However, lifelong learning remains a long-standing challenge for machine learning and neural network models since the continual acquisition of incrementally available information from non-stationary data distributions generally leads to catastrophic forgetting or interference.
The extent to which a system must be plastic in order to integrate novel information and stable in order not to catastrophically interfere with consolidated knowledge is known as the stability-plasticity dilemma and has been widely studied in both biological systems and computational models (Ditzler et al. 2015, Mermillod et al. 2013, Grossberg 1980, 2012). Due to the very challenging but high-impact aspects of lifelong learning, a large body of computational approaches have been proposed that take inspiration from the biological factors of learning from the mammalian brain.
Plasticity is an essential feature of the brain for neural malleability at the level of cells and circuits (see Power & Schlaggar (2016) a survey). For a stable continuous lifelong process, two types of plasticity are required: (i) Hebbian plasticity (Hebb 1949) for positive feedback instability, and (ii) compensatory homeostatic plasticity which stabilizes neural activity. It has been observed experimentally that specialized mechanisms protect knowledge about previously learned tasks from interference encountered during the learning of novel tasks by decreasing rates of synaptic plasticity (Cichon & Gan 2015). Together, Hebbian learning and homeostatic plasticity stabilize neural circuits to shape optimal patterns of experience-driven connectivity, integration, and functionality (Zenke, Gerstner & Ganguli 2017, Abraham & Robins 2005).
Neurosynaptic plasticity is an essential feature of the brain yielding physical changes in the neural structure and allowing us to learn, remember, and adapt to dynamic environments (see Power & Schlaggar (2016) for a survey). The brain is particularly plastic during critical periods of early development in which neural networks acquire their overarching structure driven by sensorimotor experiences. Plasticity becomes less prominent as the biological system stabilizes through a well-specified set of developmental stages, preserving a certain degree of plasticity for its adaptation and reorganization at smaller scales (Hensch et al. 1998, Quadrato et al. 2014, Kiyota 2017). The specific profiles of plasticity during critical and post-developmental periods vary across biological systems (Uylings 2006), showing a consistent tendency to decreasing levels of plasticity with increasing age (Hensch 2004). Plasticity plays a crucial role in the emergence of sensorimotor behaviour by complementing genetic information which provides a specific evolutionary path (Grossberg 2012). Genes or molecular gradients drive the initial development for granting a rudimentary level of performance from the start whereas extrinsic factors such as sensory experience complete this process for achieving higher structural complexity and performance (Hirsch & Spinelli 1970, Shatz 1996, Sur & Leamey 2001).

Schematic view of two aspects of neurosynaptic adaptation: a) Hebbian learning with homeostatic plasticity as a compensatory mechanism that uses observations to compute a feedback control signal (Adapted with permission from Zenke, Gerstner & Ganguli (2017)). b) The complementary learning systems (CLS) theory (McClelland et al. 1995) comprising the hippocampus for the fast learning of episodic information and the neocortex for the slow learning of structured knowledge.
note
Recommender systems play an increasingly important role in the current Web 2.0 era which faces with serious information overload issues. The key technique in a recommender system is the personalization model, which estimates the preference of a user on items based on the historical user-item interactions. Since users keep interacting with the system, new interaction data is collected continuously, providing the latest evidence on user preference. Therefore, it is important to retrain the model with the new interaction data, so as to provide timely personalization and avoid being stale. Ubiquitous personalized recommender systems are built to achieve two seemingly conflicting goals, to serve high quality content tailored to individual user's taste and to adapt quickly to the ever changing environment. The former requires a complex machine learning model that is trained on a large amount of data; the latter requires frequent update to the model. With the increasing complexity of recommender models, it is technically challenging to apply real-time updates on the models in an online fashion, especially for those expressive but computationally expensive deep neural networks. As such, a common practice in industry is to perform model retraining periodically, for example, on a daily or weekly basis.
Additional interference effects were observed for long-term knowledge. Pallier et al. (2003) studied the word recognition abilities of Korean-born adults whose language environment shifted completely from Korean to French after being adopted between the ages of 3 and 8 by French families. Behavioural tests showed that subjects had no residual knowledge of the previously learned Korean vocabulary. Functional brain imaging data showed that the response of these subjects while listening to Korean was no different from the response while listening to other foreign languages that they had been exposed to, suggesting that their previous knowledge of Korean was completely overwritten. Interestingly, brain activations showed that Korean-born subjects produced weaker responses to French with respect to native French speakers. It was hypothesized that, while the adopted subjects did not show strong responses to transient exposures to the Korean vocabulary, prior knowledge of Korean may have had an impact during the formulation of language skills to facilitate the reacquisition of the Korean language should the individuals be re-exposed to it in an immersive way.
Artificial agents which evolve in dynamic environments should be able to update their capabilities in order to integrate new data. Depending on the work hypotheses made, names such as continual learning, lifelong learning or incremental learning (IL) are used to describe associated works. The challenge faced in all cases is catastrophic forgetting, i.e., the tendency of a neural network to underfit past data when new ones are ingested. The effect of catastrophic forgetting is alleviated either by increasing the model capacity to accommodate new knowledge or by storing exemplars of past classes in a bounded memory and replaying them in each new state.
Human beings learn by building on their memories and applying past knowledge to understand new concepts. Unlike humans, existing neural networks (NNs) mostly learn in isolation and can be used effectively only for a limited time. Models become less accurate over time, for instance, due to the changing distribution of data – the phenomenon known as concept drift (Schlimmer and Granger, 1986; Widmer and Kubat, 1993).
Humans do not typically exhibit strong events of catastrophic forgetting because the kind of experiences we are exposed to are very often interleaved (Seidenberg & Zevin 2006). Nevertheless, forgetting effects may be observed when new experiences are strongly immersive such as in the case of children drastically shifting from Korean to French. Together, these findings reveal a well-regulated balance in which, on the one hand, consolidated knowledge must be protected to ensure its long-term durability and avoid catastrophic interference during the learning of novel tasks and skills over long periods of time. On the other hand, under certain circumstances such as immersive long-term experiences, old knowledge can be overwritten in favour of the acquisition and refinement of new knowledge.
info
Catastrophic forgetting is the tendency of neural networks to underfit past data when new ones are ingested.
Throughout the years, numerous methods have been proposed to address the challenge known as catastrophic forgetting (CF) or catastrophic interference (McCloskey and Cohen, 1989). Naive approaches to mitigate the problem, such as retraining the model from scratch to adapt to a new task (or a new data distribution), are costly and time-consuming. This is reinforced by the problems of capacity saturation and model expansion. Concretely, a parametric model, while learning data samples with different distributions or progressing through a sequence of tasks, eventually reaches a point at which no more knowledge can be stored – i.e. its representational capacity approaches the limit (Sodhani et al., 2020; Aljundi et al., 2019). At this point, either model’s capacity is expanded, or a selective forgetting – which likely incurs performance degradation – is applied. The latter choice may result either in a deterioration of prediction accuracy on new tasks (or data distributions) or forgetting the knowledge acquired before. This constraint is underpinned by a defining characteristic of Continuous Learning (CL), known as the stability-plasticity dilemma. Specifically, the phenomenon considers the model’s attempt to strike a balance between its stability (the ability to retain prior knowledge) and its plasticity (the ability to adapt to new knowledge).
There are certain desired properties (Desiderata of continual learning): 1) Knowledge retention - The model is not prone to catastrophic forgetting, 2) Forward transfer - The model learns a new task while reusing knowledge acquired from previous tasks, 3) Backward transfer - The model achieves improved performance on previous tasks after learning a new task, 4) Online learning - The model learns from a continuous data stream, 5) No task boundaries - The model learns without requiring neither clear task nor data boundaries, 6) Fixed model capacity - Memory size is constant regardless of the number of tasks and the length of a data stream.
Intuitively, the historical interactions provide more evidence on user long-term (e.g., inherent) interest and the newly collected interactions are more reflective of user short-term preference. Three retraining strategies are most widely adopted, depending on the data utilization: 1) Fine-tuning, which updates the model based on the new interactions only. This way is memory and time efficient, since only new data is to be handled. However, it ignores the historical data that contains long-term preference signal, thus can easily cause overfitting and forgetting issues, 2) Sample-based retraining, which samples historical interactions and adds them to new interactions to form the training data. The sampled interactions are expected to retain long-term preference signal, which need be carefully selected to obtain representative interactions. In terms of recommendation accuracy, it is usually worse than using all historical interactions due to the information loss caused by sampling, and 3) Full retraining, which trains the model on the whole data that includes all historical and new interactions. Undoubtedly, this method costs most resources and training time, but it provides the highest model fidelity since all available interactions are utilized.
Although full model retraining provides the highest fidelity, it is not necessary to do so. The key reason is that the historical interactions have been trained in the previous training, which means the model has already distilled the “knowledge” from the historical data. If there is a way to retain the knowledge well and transfer it to the training on new interactions, we should be able to keep the same performance level as the full retraining, even though we do not use the historical data during model retraining. Furthermore, if the knowledge transfer is “smart” enough to capture more patterns like recent data is more reflective of near future performance, we even have the opportunity to improve over the full retraining in recommendation accuracy.
info
Different name, same thing: Online learning, Incremental learning, Sequential learning, Iterative learning, Continuous learning, Out-of-core learning.
Classic machine learning algorithms are mostly based on batch learning, i.e., the model is trained on a fixed dataset, then deployed for online inference. The assumption is that one can afford to wait until the data is accumulated before a new model is trained. This paradigm does not apply well to data streams where the model needs to be updated before a full dataset is available. Incremental learning fills the gap by learning from the few newly available samples without resorting to a full training. Similar concepts such as online learning, continual learning (Gepperth and Hammer, 2016; Parisi et al., 2019; Delange et al., 2021) appear in different contexts in the literature.
In order to keep up with the latest trend, it is tempting to take the last trained model as an initial start point, then continue to train it on the latest dataset, known as warm start. However, the model tends to overfit on the new dataset and forget what has been learned so far. This phenomenon is often referred to as catastrophic forgetting (Goodfellow et al., 2013). This problem can be mitigated if we train models on both the past and the latest datasets. This however results in the ever growing training time which conflicts with the goal of a fast model refreshing rate.
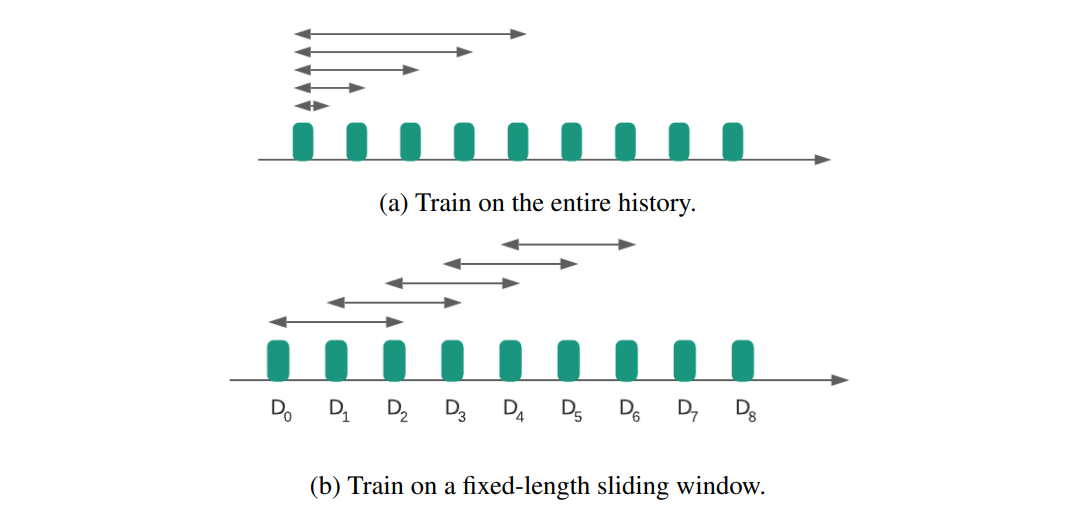
Suppose there is a stream of datasets indexed by time. At time t, we have access to . Our goal is to build a model based on the stream. As illustrated in the above figure, one approach is to train the model on the entire history . The training datasets quickly grow overwhelmingly large. To constrain the training dataset size, we can place a fixed length sliding window on the stream, only the datasets inside the window are used for training as in the above figure. For example, if at time we choose window size to train the model, we are using . This approach retrains the entire model even if there is only one more new dataset, which does not scale well with a large window length. Another approach is to use a small window length for retraining but initialize the model coefficients based on the model trained previously. For example, we set = 1 and use the model at to initialize the model training at time . This approach, named as warm start, can improve the training efficiency but may result in a model that forgets what is learned in the past.
We can use incremental learning approach to address both aspects of the model training. (1) Model training speed: since we only need to train on the incremental portion of data, faster training speed is achieved; (2) Model quality: key quantities from the previous training are used to construct an informative prior, so the model remembers the essential information from the past data and learn new information from the latest training data.
We observe performance degradation when the recommendation model stops updating in a mainstream recommendation service which may lead to significant loss of revenue and a poor user experience. However, directly retraining the model using only the recent records often causes a catastrophic forgetting problem, with the model losing track of the key user information needed to capture long term preferences. Incremental learning provides one direction for tackling this problem. Incremental learning uses the most recent data to update the current model, but is designed to prevent substantial forgetting. This significantly improves training efficiency without extra computational resource and meanwhile prevents model performance degradation.
Modern online web-based systems continuously generate data at very fast rates. This continuous flow of data encompasses web content – e.g. posts, news, products, comments -, but also user feedback – e.g. ratings, views, reads, clicks, thumbs up -, as well as context information – device, geographic info, social network, current user activity, weather. This is potentially overwhelming for systems and algorithms design to train in offline batches, given the continuous and potentially fast change of content, context and user preferences. Therefore it is important to investigate online methods to be able to transparently adapt to the inherent dynamics of online systems. Incremental models that learn from data streams are gaining attention in the recommender systems community, given their natural ability to deal with data generated in dynamic, complex environments. User modeling and personalization can particularly benefit from algorithms capable of maintaining models incrementally and online, as data is generated.
There are three main lines of work for incremental learning: experience replay (reservoir), parameter isolation and regularization based methods. Reservoir methods use an additional data reservoir to store the most representative historical data and replay it while learning new tasks to alleviate forgetting. Parameter isolation trains distinct models for different tasks, but leads to continual growth of the model size which is not favourable for training large-scale systems. Regularization based approaches aim to consolidate previous knowledge by introducing regularization terms in the loss when learning on new data.
Key considerations
- When should a model be retrained? - Periodic training, Performance-based trigger, Trigger based on Data changes, Retraining on demand.
- How much data is needed for retraining? - Fixed window, Dynamic window, Representative Subsample selection.
- What should be retrained? - Continual learning vs Transfer learning, Offline(batch) Vs Online(Incremental).
- When to deploy your model after retraining? - A/B testing.
Continual Learning
Methods developed for continual learning generally fall under three categories: experience replay, regularization-based methods, and model fusion. Experience replay prevents forgetting by reusing past samples together with the new data to update the model. Generative methods are later on developed to alleviate the burden of storing real data. Regularization-based methods retain past knowledge by constraining the parameters update based on some measure of importance. Some works also employ distillation techniques to regularize the update direction. Model fusion supports continual learning of tasks by gradually incorporating sub-networks. Both expandable and fixed-size network methods are developed.
Catastrophic Forgetting
Catastrophic forgetting is a well-known issue in retraining ML models. Continual learning is a field of study that specifically tackles this problem, which has developed effective methods for applications in Computer Vision (CV) and Natural Language Processing (NLP). However, when it comes to RSs incremental update, directly adopting these methods may not lead to desirable outcomes. This is because the two problems have different ultimate goals: continual learning aims to perform well for the current task without sacrificing performance on previous tasks, while incremental update of RSs only cares about the performance on future tasks. Hence, the main focus of incremental update lies in how to effectively transfer past knowledge especially useful for future predictions.
Sample-based vs Model-based methods
To overcome the specific forgetting issue in RSs incremental update, two lines of research have been developed inspired by some of the methods in continual learning, namely sample-based approach and model-based approach. Despite the effectiveness of both approaches, there exist some major limitations. For the sample-based approach, although the individual samples are carefully selected to be the ‘informative’ ones, they can hardly represent the big picture of the overall distribution. To tackle this, the model-based approach which considers transfer of knowledge between past and present models was recently proposed. However, a major limitation of the existing model-based methods is that, none of them explores the potential of the long-term sequential patterns exist in model evolution, which can be very useful information for generating a better model for future serving.
Incremental Learning in Computer Vision
Three continual learning scenarios in the context of computer vision

In the first scenario, models are always informed about which task needs to be performed. This is the easiest continual learning scenario, and we refer to it as task-incremental learning (Task-IL). Since task identity is always provided, in this scenario it is possible to train models with task-specific components. A typical network architecture used in this scenario has a “multi-headed” output layer, meaning that each task has its own output units but the rest of the network is (potentially) shared between tasks. Example - With task given, is it the 1st or 2nd class? (e.g., 0 or 1).
In the second scenario, which we refer to as domain-incremental learning (Domain-IL), task identity is not available at test time. Models however only need to solve the task at hand; they are not required to infer which task it is. Typical examples of this scenario are protocols whereby the structure of the tasks is always the same, but the input-distribution is changing. A relevant real-world example is an agent who needs to learn to survive in different environments, without the need to explicitly identify the environment it is confronted with. Example - With task unknown, is it a 1st or 2nd class? (e.g., in [0, 2, 4, 6, 8] or in [1, 3, 5, 7, 9]).
Finally, in the third scenario, models must be able to both solve each task seen so far and infer which task they are presented with. We refer to this scenario as class-incremental learning (Class-IL), as it includes the common real-world problem of incrementally learning new classes of objects. Example - With task unknown, which digit is it? (i.e., choice from 0 to 9).

References
- How to Retrain Recommender System? A Sequential Meta-Learning Method. Yang Zhang, Fuli Feng, Chenxu Wang, Xiangnan He, Meng Wang, Yan Li, Yongdong Zhang. 2020. arXiv. https://arxiv.org/abs/2005.13258
- Lambda Learner: Fast Incremental Learning on Data Streams. Rohan Ramanath, Konstantin Salomatin, Jeffrey D. Gee, Kirill Talanine, Onkar Dalal, Gungor Polatkan, Sara Smoot, Deepak Kumar. 2020. arXiv. https://arxiv.org/abs/2010.05154
- Online-Updating Regularized Kernel Matrix Factorization Models for Large-Scale Recommender Systems. Steffen Rendle, Lars Schmidt-Thieme. 2008. RecSys. https://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.165.8010&rep=rep1&type=pdf
- Neural Memory Streaming Recommender Networks with Adversarial Training. Wang et. al.. 2018. KDD. https://www.kdd.org/kdd2018/accepted-papers/view/neural-memory-streaming-recommender-networks-with-adversarial-training
- Causal Incremental Graph Convolution for Recommender System Retraining. Sihao Ding, Fuli Feng, Xiangnan He, Yong Liao, Jun Shi, Yongdong Zhang. 2021. arXiv. https://arxiv.org/abs/2108.06889v1
- GraphSAIL: Graph Structure Aware Incremental Learning for Recommender Systems. Yishi Xu, Yingxue Zhang, Wei Guo, Huifeng Guo, Ruiming Tang, Mark Coates. 2020. arXiv. https://arxiv.org/abs/2008.13517
- Incremental Learning for Personalized Recommender Systems. Yunbo Ouyang, Jun Shi, Haichao Wei, Huiji Gao. 2021. arXiv. https://arxiv.org/abs/2108.13299
- A Practical Incremental Method to Train Deep CTR Models. Yichao Wang, Huifeng Guo, Ruiming Tang, Zhirong Liu, Xiuqiang He. 2020. arXiv. https://arxiv.org/abs/2009.02147
- Creme. Max Halford. 2019. https://maxhalford.github.io/slides/creme-pydata
- Continual Lifelong Learning in Natural Language Processing: A Survey. Magdalena Biesialska, Katarzyna Biesialska, Marta R. Costa-jussà. 2020. arXiv. https://aclanthology.org/2020.coling-main.574/
- Online Continual Learning in Image Classification: An Empirical Survey. Zheda Mai, Ruiwen Li, Jihwan Jeong, David Quispe, Hyunwoo Kim, Scott Sanner. 2021. arXiv. https://arxiv.org/abs/2101.10423
- Class-incremental learning: survey and performance evaluation on image classification. Marc Masana, Xialei Liu, Bartlomiej Twardowski, Mikel Menta, Andrew D. Bagdanov, Joost van de Weijer. 2020. arXiv. https://arxiv.org/abs/2010.15277
- A Comprehensive Study of Class Incremental Learning Algorithms for Visual Tasks. Eden Belouadah, Adrian Popescu, Ioannis Kanellos. 2020. arXiv. https://arxiv.org/abs/2011.01844
- Three scenarios for continual learning. Gido M. van de Ven, Andreas S. Tolias. 2019. arXiv. https://arxiv.org/abs/1904.07734v1
- Continual Lifelong Learning with Neural Networks: A Review. German I. Parisi, Ronald Kemker, Jose L. Part, Christopher Kanan, Stefan Wermter. 2018. arXiv. https://arxiv.org/abs/1802.07569
- Retraining Model During Deployment: Continuous Training and Continuous Testing. Akinwande Komolafe. 2021. https://neptune.ai/blog/retraining-model-during-deployment-continuous-training-continuous-testing
- To retrain, or not to retrain? Let's get analytical about ML model updates. 2021. https://evidentlyai.com/blog/retrain-or-not-retrain
- Quickstart Guide to Automating Model Retraining. Luigi Patruno. 2019. https://attachments.convertkitcdnn.com/114701/c81d33b7-db8b-47ee-b10b-7a37797f8848/quickstart_model_retraining.pdf
- Common pitfalls in training and evaluating recommender systems. Hung-Hsuan Chen, Chu-An Chung, Hsin-Chien Huang, Wen Tsui. 2017. KDD. https://www.kdd.org/exploration_files/19-1-Article3.pdf
- Fast Incremental Matrix Factorization for Recommendation with Positive-Only Feedback. Joao Vinagre, Alipio Mario Jorge, and Joao Gama. 2014. arXiv. https://asset-pdf.scinapse.io/prod/30495595/30495595.pdf
- GLMix: Generalized Linear Mixed Models For Large-Scale Response Prediction. Xianxing Zhang, Yitong Zhou, Yiming Ma, Bee-Chung Chen, Liang Zhang, Deepak Agarwal. 2016. KDD. https://www.kdd.org/kdd2016/papers/files/adf0562-zhangA.pdf
- Scikit-Multiflow: A Multi-output Streaming Framework. Jacob Montiel, Jesse Read, Albert Bifet, Talel Abdessalem. 2018. arXiv. https://arxiv.org/abs/1807.04662