Bias & Fairness
It can’t be denied that there is bias all around us. A bias is a prejudice against a person or group of people, including, but not limited to their gender, race, and beliefs. Many of these biases arise from emergent behavior in social interactions, events in history, and cultural and political views around the world. These biases affect the data that we collect. Because AI algorithms work with this data, it is an inherent problem that the machine will “learn” these biases. From a technical perspective, we can engineer the system perfectly, but at the end of the day, humans interact with these systems, and it’s our responsibility to minimize bias and prejudice as much as possible. The algorithms we use are only as good as the data provided to them. Understanding the data and the context in which it is being used is the first step in battling bias, and this understanding will help you build better solutions—because you will be well versed in the problem space. Providing balanced data with as little bias as possible should result in better solutions.
Recommender systems are important for connecting users to the right items. But are items recommended fairly? For example, in a recruiting recommender that recommends job candidates (the items here), are candidates of different genders treated equally? In a news recommender, are news stories with different political ideologies recommended fairly? And even for product recommenders, are products from big companies favored over products from new entrants? The danger of unfair recommendations for items has been recognized in the literature, with potential negative impacts on item providers, user satisfaction, the recommendation platform itself, and ultimately social good.
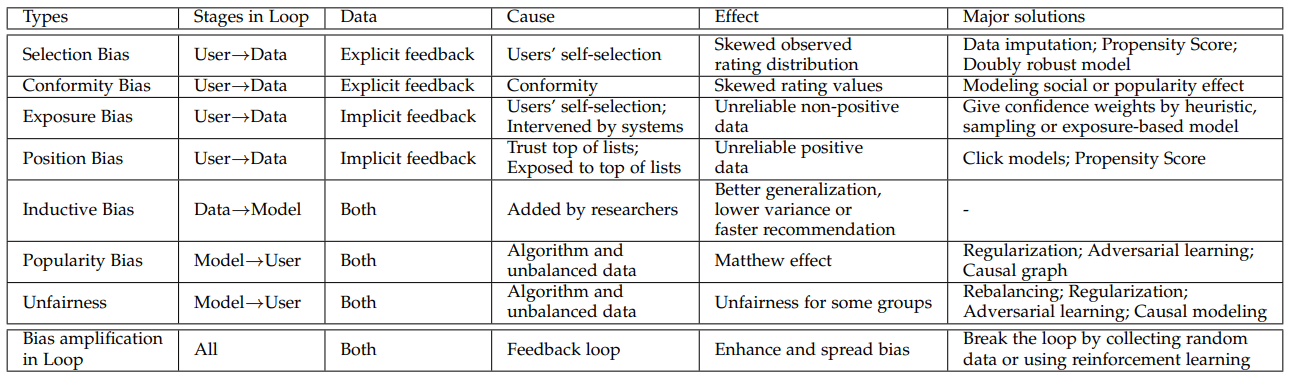
In practice, the data is observational rather than experimental, and is often affected by many factors, including but not limited to self-selection of the user (selection bias), exposure mechanism of the system (exposure bias), public opinions (conformity bias) and the display position (position bias). De-biasing the data is an important and critical pre-processing step. Biases cause training data distribution deviate from the ideal unbiased one.
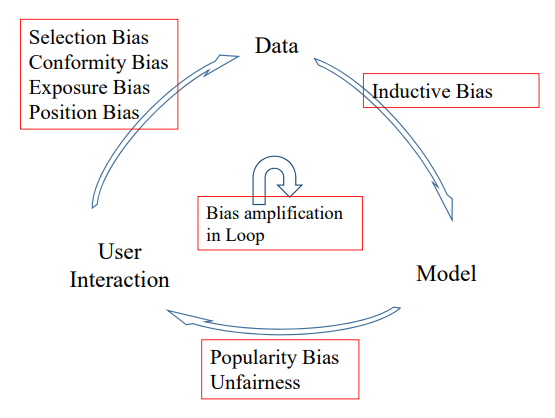
Types of biases
Selection bias
Selection bias originates from users’ numerical ratings on items (i.e., explicit feedback), which is defined as - "Selection Bias happens as users are free to choose which items to rate, so that the observed ratings are not a representative sample of all ratings. In other words, the rating data is often missing not at random (MNAR)."
 paper.](/ai-kb/assets/images/content-concepts-raw-bias-&-fairness-untitled-2-783d9b3c06b9edb7a88c0c717f6e8d17.png)
Distribution of rating values for randomly selected items and user-selected items, as demonstrated in this paper.
Conformity bias
Another bias inherent in the explicit feedback data is conformity bias, which is defined as: "Conformity bias happens as users tend to rate similarly to the others in a group, even if doing so goes against their own judgment, making the rating values do not always signify user true preference".
For example, influenced by high ratings of public comments on an item, one user is highly likely to change her low rate, avoiding being too harsh. Such phenomenon of conformity is common and cause biases in user ratings. As shown in Krishnan et al., user ratings follow different distributions when users rate items before or after being exposed to the public opinions. Moreover, conformity bias might be caused by social influence, where users tend to behave similarly with their friends. Hence, the observed ratings are skewed and might not reflect users’ real preference on items.
Debiasing methods
IPS
IPS eliminates popularity bias by re-weighting each instance according to item popularity. Specifically, weight for an instance is set as the inverse of corresponding item popularity value, hence popular items are imposed lower weights, while the importance for long-tail items are boosted.
IPS-C
This method adds max-capping on IPS value to reduce the variance of IPS.
IPS-CN
This method further adds normalization which also achieved lower variance than plain IPS, at the expense of introducing a small amount of bias.
IPS-CNSR
Smoothing and re-normalization are added to attain more stable output of IPS.
CausE
This method requires a large biased dataset and a small unbiased dataset. Each user or item has two embeddings to perform matrix factorization (MF) on the two datasets respectively, and L1 or L2 regularization is exploited.
Random
Aim for ethical and legal applications of technology
Concepts
Equal opportunity
In a classification task, equal opportunity requires a model to produce the same true positive rate (TPR) for all individuals or groups. The goal is to ensure that items from different groups can be equally recommended to matched users during testing (the same true positive rate): for example, candidates of different genders are equally recommended to job openings that they are qualified for. In contrast, demographic parity fairness only focuses on the difference in the amount of exposure to users without considering the ground-truth of user-item matching. However, because only the exposure to matched users (as considered by equal opportunity fairness) can influence the feedback or economic gain of items, in recommendation tasks, equal opportunity is better aligned than demographic parity fairness.
Rawlsian Max-Min fairness principle of distributive justice
Rawlsian Max-Min fairness requires a model to maximize the minimum utility of individuals or groups so that no subject is underserved by the model. Unlike equality (or parity) based notions of fairness aiming to eliminate difference among individuals or groups but neglecting a decrease of utility for betterserved subjects, Rawlsian Max-Min fairness accepts inequalities and thus does not requires decreasing utility of better-served subjects. So, Rawlsian Max-Min fairness is preferred in applications where perfect equality is not necessary, such as recommendation tasks, and it can also better preserve the overall model utility.
AutoDebias
AutoDebias is an automatic debiasing method for recommendation system based on meta learning, exploiting a small amount of uniform data to learn de-biasing parameters and using these parameters to guide the learning of the recommendation model.
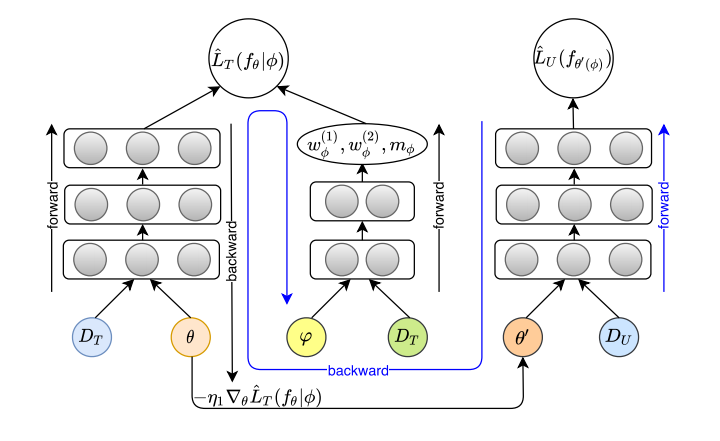
The working flow of AutoDebias, consists of three steps: (1) tentatively updating 𝜃 to 𝜃 ′ on the training data 𝐷𝑇 with current 𝜙 (black arrows); (2) updating 𝜙 based on 𝜃 ′ on the uniform data (blue arrows); (3) actually updating 𝜃 with the updated 𝜙 (black arrows).