Language Modeling
Language Models (LMs) estimate the probability of different linguistic units: symbols, tokens, token sequences.
We see language models in action every day - look at some examples. Usually models in large commercial services are a bit more complicated than the ones we will discuss today, but the idea is the same: if we can estimate probabilities of words/sentences/etc, we can use them in various, sometimes even unexpected, ways.
We, humans, already have some feeling of "probability" when it comes to natural language. For example, when we talk, usually we understand each other quite well (at least, what's being said). We disambiguate between different options which sound similar without even realizing it!
But how a machine is supposed to understand this? A machine needs a language model, which estimates the probabilities of sentences. If a language model is good, it will assign a larger probability to a correct option.
Read this article to understand the concept of language models in depth.
Masked language modeling
Masked language modeling is the task of training a model on input (a sentence with some masked tokens) and obtaining the output as the whole sentence with the masked tokens filled. But how and why does it help a model to obtain better results on downstream tasks such as classification? The answer is simple: if the model can do a cloze test (a linguistic test for evaluating language understanding by filling in blanks), then it has a general understanding of the language itself. For other tasks, it has been pretrained (by language modeling) and will perform better.

Here's an example of a cloze test:
George Washington was the first President of the ___ States.
It is expected that United should fill in the blank. For a masked language model, the same task is applied, and it is required to fill in the masked tokens. However, masked tokens are selected randomly from a sentence.
In BERT4Rec, authors used Cloze task technique (also known as “Masked Language Model) to train the bi-directional model. In this, we randomly mask some items (i.e., replace them with a special token [mask]) in the input sequences, and then predict the ids of those masked items based on their surrounding context.
Let's take another example:
In Autumn the __ fall from the trees.
Do you know the answer? Most likely you do, and you do because you have considered the context of the sentence.
We see the words fall and trees — we know that the missing word is something that falls from trees.
A lot of things fall from trees, acorns, branches, leaves — but we have another condition, in Autumn — that narrows down our search, the most probable thing to fall from a tree in Autumn are leaves.
As humans, we use a mix of general world knowledge, and linguistic understanding to come to that conclusion. For BERT, this guess will come from reading a lot — and learning linguistic patterns incredibly well.
BERT may not know what Autumn, trees, and leaves are — but it does know that given linguistic patterns, and the context of these words, the answer is most likely to be leaves.
The outcome of this process — for BERT — is an improved comprehension of the style of language being used.
Causal language modeling
Causal language modeling is the task of predicting the token following a sequence of tokens. In this situation, the model only attends to the left context (tokens on the left of the mask). Such a training is particularly interesting for generation tasks.
Permutation language modeling
PLM is the idea of capturing bidirectional context by training an autoregressive model on all possible permutation of words in a sentence. Instead of fixed left-right or right-left modeling, XLNET maximizes expected log likelihood over all possible permutations of the sequence. In expectation, each position learns to utilize contextual information from all positions thereby capturing bidirectional context. No [MASK] is needed and input data need not be corrupted.
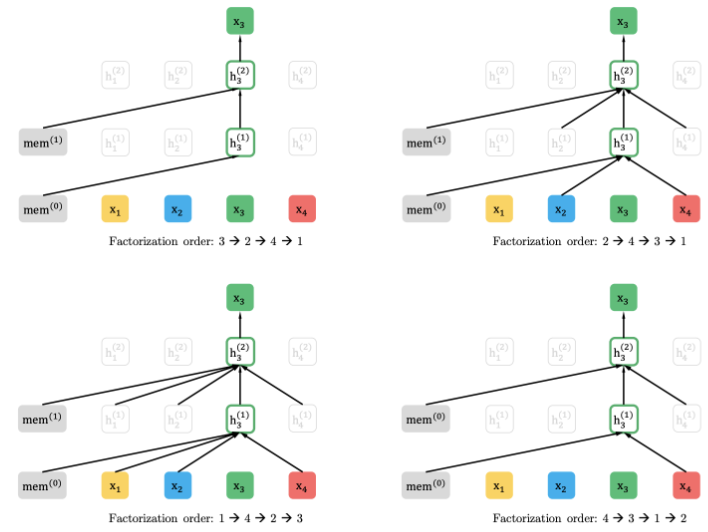
The above diagram illustrates PLM. Let us consider that we are learning x3 (the token at the 3rd position in the sentence). PLM trains an autoregressive model with various permutations of the tokens in the sentence, so that in the end of all such permutations, we would have learnt x3, given all other words in the sentence. In the above illustration, we can see that the next layer takes as inputs only the tokens preceding x3 in the permutation sequence. This way, autoregression is also achieved.