Text Summarization

Automatic Text Summarization gained attention as early as the 1950’s. A research paper, published by Hans Peter Luhn in the late 1950s, titled “The automatic creation of literature abstracts”, used features such as word frequency and phrase frequency to extract important sentences from the text for summarization purposes.
Another important research, done by Harold P Edmundson in the late 1960’s, used methods like the presence of cue words, words used in the title appearing in the text, and the location of sentences, to extract significant sentences for text summarization. Since then, many important and exciting studies have been published to address the challenge of automatic text summarization.
Text summarization can broadly be divided into two categories — Extractive Summarization and Abstractive Summarization.
- Extractive Summarization: These methods rely on extracting several parts, such as phrases and sentences, from a piece of text and stack them together to create a summary. Therefore, identifying the right sentences for summarization is of utmost importance in an extractive method.
- Abstractive Summarization: These methods use advanced NLP techniques to generate an entirely new summary. Some parts of this summary may not even appear in the original text.
Introduction
- Definition: To take the appropriate action, we need the latest information, but on the contrary, the amount of information is more and more growing. Making an automatic & accurate summaries feature will helps us to understand the topics and shorten the time to do it.
- Applications: News Summarization, Social media Summarization, Entity timelines, Storylines of event, Domain specific summaries, Sentence Compression, Event understanding, Summarization of user-generated content
- Scope: Extractive and Abstractive summary
- Single document summarization: summary = summarize(document)
- Multi-document summarization: summary = summarize(document_1, document_2, ...)
- Query focused summarization: summary = summarize(document, query)
- Update summarization: summary = summarize(document, previous_document_or_summary)
- Tools: HuggingFace Transformer Library
Scheduled sampling
In the inference (testing) phase, the model only depends on the previous step, which means that it totally depends on itself. The problem actually arises when the model results in a bad output in (t-1) (i.e. the previous time step results in a bad output). This would actually affect all the coming sequences. It would lead the model to an entirely different state space from where it has seen and trained on in the training phase, so it simply won’t be able to know what to do. A solution to this problem that has been suggested by bengio et ai from google research, was to gradually change the reliance of the model from being totally dependent on the ground truth being supplied to it to depending on itself (i.e. depend on only its previous tokens generated from previous time steps in the decoder). The concept of making the learning path difficult through time (i.e. making the model depends on only itself) is called curriculum learning. Their technique to implement this was truly genius. They call it ‘scheduled sampling’.
-5f8409e2607f0b09a07bf3afd2bb425b.png)
Landscape of seq2seq models for neural abstractive text summarization
Models
ProphetNet
ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training. arXiv, 2020.
PEGASUS
PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization. arXiv, 2019.
BERTSum
Fine-tune BERT for Extractive Summarization. arXiv, 2019.
Seq2Seq PointerGenerator
Get To The Point: Summarization with Pointer-Generator Networks. arXiv, 2017.
Process flow
Step 1: Collect Text Data
Fetch the raw text dataset into a directory.
Step 2: Create Labels
Step 3: Model Training & Validation
Step 4: UAT Testing
Wrap the model inference engine in API for client testing. We will receive a text document from the user, encode it with our text encoder, find TopK similar vectors using Indexing object, and retrieve the text documents (and metadata) using dictionaries. We send these documents (and metadata) back to the user.
Step 5: Deployment
Deploy the model on cloud or edge as per the requirement.
Step 6: Documentation
Prepare the documentation and transfer all assets to the client.
Use Cases
Enron Email Summarization
Email overload can be a difficult problem to manage for both work and personal email inboxes. With the average office worker receiving between 40 to 90 emails a day, it has become difficult to extract the most important information in an optimal amount of time. A system that can create concise and coherent summaries of all emails received within a timeframe can reclaim a large amount of time. Check out this notion.
PDF Summarization over mail
Built a system that will receive a pdf over outlook mail and create a word cloud for this pdf. Then, send this word cloud back as an attachment to that email. Check out this notion.
BART Text Summarization
Document text summarization using the BART transformer model and visual API using the Plotly Dash app. Check out this notion.
Transformers Summarization Experiment
Experiment with various transformers for text summarization using HuggingFace library. Summarization of 4 books. Check out this notion.
CNN-DailyMail and InShorts News Summarization
Check out this notion for CNN-DailyMail and this one for InShorts.
Transformers Summarization Experiment
Experiment with various transformers for text summarization using HuggingFace library. Summarization of 4 books. Check out this notion.
Covid-19 article summarization
Used BERT and GPT-2 for article summarization related to covid-19. Check out this notion.
Common Applications
- News Summarization: The summarization systems leverage the power of multi-document summarization techniques in order to summarize the news coming from various sources. It generates a compact summary that is informative and non-redundant. Methods used can be extractive or abstractive. For example, the ’Inshort’ application generates a sixty-word summary of news articles.
- Social media Summarization: deals with the summarization of social media text such as: tweets, blogs, community forums, etc. These summarization systems are built keeping in mind the needs of the user and are dependent on the genre of social media text. Tweets summarization system will be different from blog summarization systems as tweets have a short text (140 characters) and are often noisy. While the blog has considerably longer length text with a different writing style.
- Entity timelines: The system generates the summary of most salient events related to an entity within a given timeline. The news collections from various news sources are collected over a period of time. Each of these news collections define a main event. For a given entity, these news collection are identified and ranked in order of importance. Most salient sentences with respect to the given entity is selected from each of these news cluster to finally generate an entity timeline.
- Storylines of event: deals with identifying and summarization of events that leads to event of interest. It helps in providing background information about an event and structured timeline for an entity. The news collections from various news sources are collected over a period of time. Each of these news collections define a main even. A graph of events (news collection) is defined using similarity, then heaviest path ending in a given event is identified and finally, the events on this path related to salient entities in target event are summarized to obtain storylines of the event.
- Domain specific summaries: Summarization systems are often used in generating domain specific summaries. These systems are designed in accordance with the needs of the user for a specific domain. For example: legal document summarization deals with generating summary out of a legal/law documents, medical report summarization has aim of generating a summary form a patient report history such that it includes all important clinical events in order of timeline.
- Sentence Compression: generates a short version of a longer sentence. The system is trained using a parallel corpus containing headlines of news articles and first sentence of the same article. The headline is assumed to be shorter version of the first sentence. Recent works based on abstractive neural network approaches has proven to generate high quality compressed sentences.
- Event understanding: is understanding the way events are referred to in the text and representing these event mentioning text in predicate argument structure. For example: Michael marries Sara is represented as [actor] marries [actor]. It is very helpful for semiautomatically updation of knowledge graphs and also for the task of generating headlines (abstractive summarization).
- Summarization of usergenerated content: deals with summarizing user generated contents like youtube comments, reviews of products, opinions etc. compact version of reviews and comment are very helpful in identifying overall sentiment of mass towards a particular product or topic. Which are often used by the consumers as well as the platform itself in recommending products.
Variations
- Single document summarization: summary = summarize(document)
- Multi-document summarization: summary = summarize(document_1, document_2, ...)
- Query focused summarization: summary = summarize(document, query)
- Update summarization: summary = summarize(document, previous_document_or_summary)
Basically, we can regard the "summarization" as the "function" its input is document and output is summary. And its input & output type helps us to categorize the multiple summarization tasks.
- Single document summarization
- summary = summarize(document)
- Multi-document summarization
- summary = summarize(document_1, document_2, ...)
We can take the query to add the viewpoint of summarization.
- Query focused summarization
- summary = summarize(document, query)
This type of summarization is called "Query focused summarization" on the contrary to the "Generic summarization". Especially, a type that set the viewpoint to the "difference" (update) is called "Update summarization".
- Update summarization
- summary = summarize(document, previous_document_or_summary)
And the "summary" itself has some variety.
- Indicative summary
- It looks like a summary of the book. This summary describes what kinds of the story, but not tell all of the stories especially its ends (so indicative summary has only partial information).
- Informative summary
- In contrast to the indicative summary, the informative summary includes full information of the document.
- Keyword summary
- Not the text, but the words or phrases from the input document.
- Headline summary
- Only one line summary.
Summary Variations
- Indicative summary: It looks like a summary of the book. This summary describes what kinds of the story, but not tell all of the stories especially its ends (so indicative summary has only partial information).
- Informative summary: In contrast to the indicative summary, the informative summary includes full information of the document.
- Keyword summary: Not the text, but the words or phrases from the input document.
- Headline summary: Only one line summary.
Seq2Seq
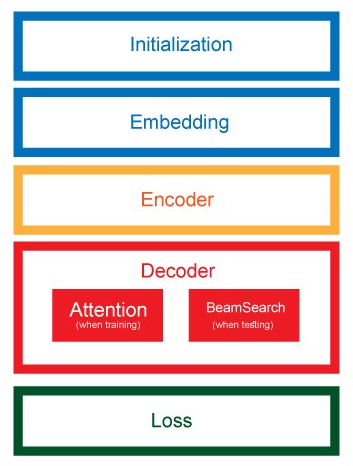
- Seq2seq - mainly bi-LSTM for encoder and attention mechanism for decoder network
Pointer Generator
-acb7a882474e5ded1e7202a839f109aa.png)
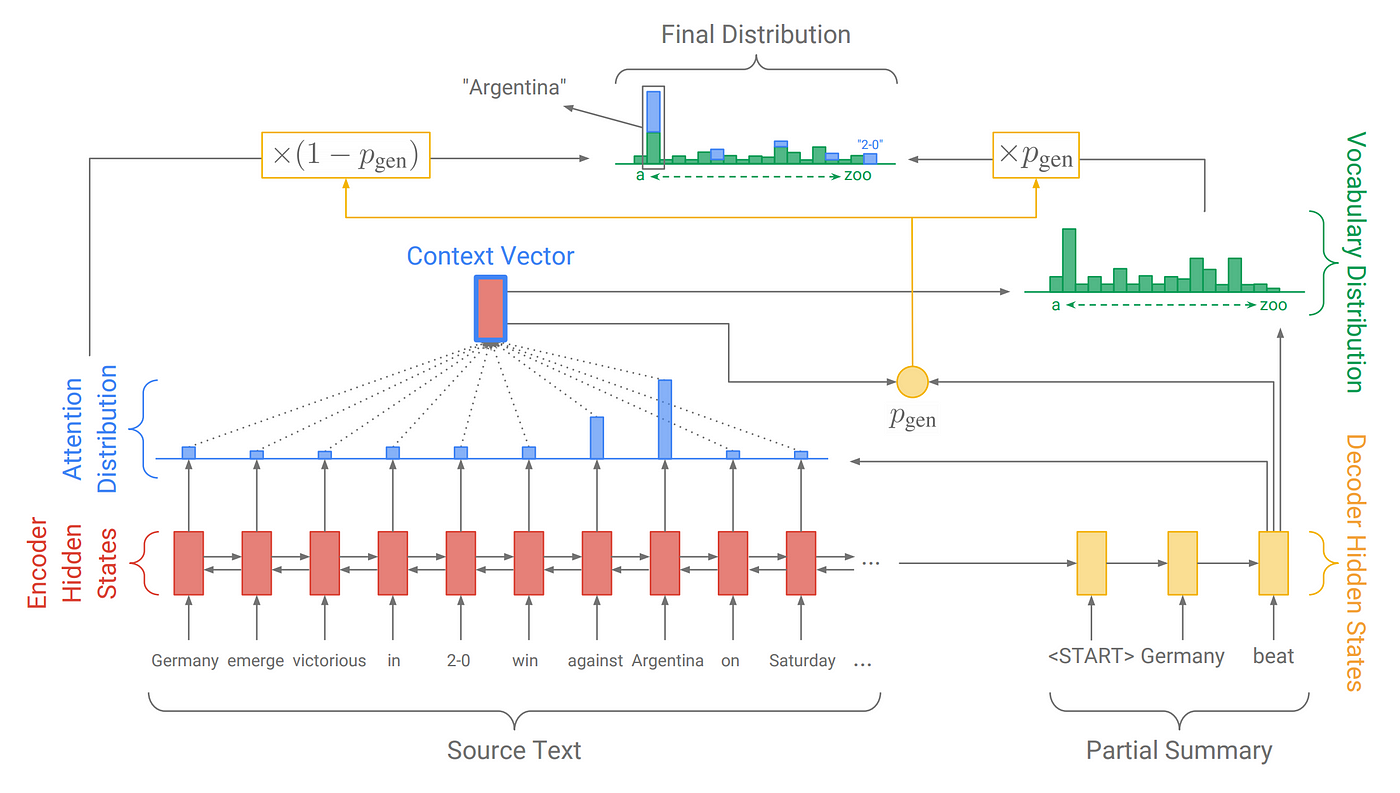
Researchers found 2 main problems with the seq2seq model, as discussed in this truly amazing blog, which is 1) the inability of the network to copy facts and 2) repetition of words. The pointer generator network (with coverage mechanism) tried to address these problems.
Experiments
theamrzaki/text_summurization_abstractive_methods
dongjun-Lee/text-summarization-tensorflow
nikhilcss97/Text-Summarization
How to Summarize Amazon Reviews with Tensorflow
- Text summarisation with BART & T5 using HuggingFace
- TextRank, Summy and BERT Summarizer
- TED Talk Tag Generator and Summarizer
Benchmark datasets
BigPatent
Most existing text summarization datasets are compiled from the news domain, where summaries have a flattened discourse structure. In such datasets, summary-worthy content often appears in the beginning of input articles. Moreover, large segments from input articles are present verbatim in their respective summaries. These issues impede the learning and evaluation of systems that can understand an article’s global content structure as well as produce abstractive summaries with high compression ratio. In this work, we present a novel dataset, BIGPATENT, consisting of 1.3 million records of U.S. patent documents along with human written abstractive summaries.
Compared to existing summarization datasets, BigPatent has the following properties:
- summaries contain richer discourse structure with more recurring entities,
- salient content is evenly distributed in the input, and
- lesser and shorter extractive fragments present in the summaries.
We train and evaluate baselines and popular learning models on BIGPATENT to shed light on new challenges and motivate future directions for summarization research.
CNN and DailyMail
CNN daily mail dataset consists of long news articles(an average of ~800 words). It consists of both articles and summaries of those articles. Some of the articles have multi line summaries also. We have used this dataset in our Pointer Generator model.
CNN dataset contains the documents from the news articles of CNN. There are approximately 90k documents/stories. DM dataset contains the documents from the news articles of Daily Mail. There are approximately 197k documents/stories. OTHR contains a few thousands stories scraped from 4 news websites.
- CNN/DM - the news body is used as the input for our model , while the header would be used as the summary target output.
- Data can be acquired from this gdrive.
Amazon Fine Food Reviews
https://www.kaggle.com/snap/amazon-fine-food-reviews
DUC-2014
- DUC-2014 dataset that involves generating approximately 14-word summaries for 500 news articles. The data for this task consists of 500 news articles from the New York Times and Associated Press Wire services each paired with 4 different human-generated reference summaries (not actually headlines), capped at 75 bytes.
Gigaword
It is popularly known as GIGAWORLD dataset and contains nearly ten million documents (over four billion words) of the original English Gigaword Fifth Edition. It consists of articles and their headlines. We have used this dataset to train our Abstractive summarization model.
Cornell Newsroom
Cornell Newsroom Summarization Dataset
Opinosis
Opinosis Dataset - Topic related review sentences | Kavita Ganesan
This dataset contains sentences extracted from user reviews on a given topic. Example topics are “performance of Toyota Camry” and “sound quality of ipod nano”, etc. The reviews were obtained from various sources — Tripadvisor (hotels), Edmunds.com (cars) and amazon.com (various electronics).Each article in the dataset has 5 manually written “gold” summaries. This dataset was used to score the results of the abstractive summarization model.
Evaluation metrics
ROGUE
Rouge-N is a word N-gram count that matche between the model and the gold summary. It is similart to the "recall" because it evaluates the covering rate of gold summary, and not consider the not included n-gram in it.
ROUGE-1 and ROUGE-2 is usually used. The ROUGE-1 means word base, so its order is not regarded. So "apple pen" and "pen apple" is same ROUGE-1 score. But if ROUGE-2, "apple pen" becomes single entity so "apple pen" and "pen apple" does not match. If you increase the ROUGE-"N" count, finally evaluates completely match or not.
BLEU
BLEU is a modified form of "precision", that used in machine translation evaluation usually. BLEU is basically calculated on the n-gram co-occerance between the generated summary and the gold (You don't need to specify the "n" unlike ROUGE).
Library
Awesome List
mathsyouth/awesome-text-summarization
References
Neural Abstractive Text Summarization with Sequence-to-Sequence Models: A Survey
A Survey on Neural Network-Based Summarization Methods
Papers with Code - A Neural Attention Model for Abstractive Sentence Summarization
Text summarization with TensorFlow
Papers with Code - Get To The Point: Summarization with Pointer-Generator Networks
Abstractive Text Summarization Using Sequence-to-Sequence RNNs and Beyond
A Deep Reinforced Model for Abstractive Summarization
Actor-Critic based Training Framework for Abstractive Summarization
Papers with Code - MASS: Masked Sequence to Sequence Pre-training for Language Generation
Papers with Code - Deep Reinforcement Learning For Sequence to Sequence Models
Papers with Code - Text Summarization with Pretrained Encoders
Papers with Code - ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training