Text Classification
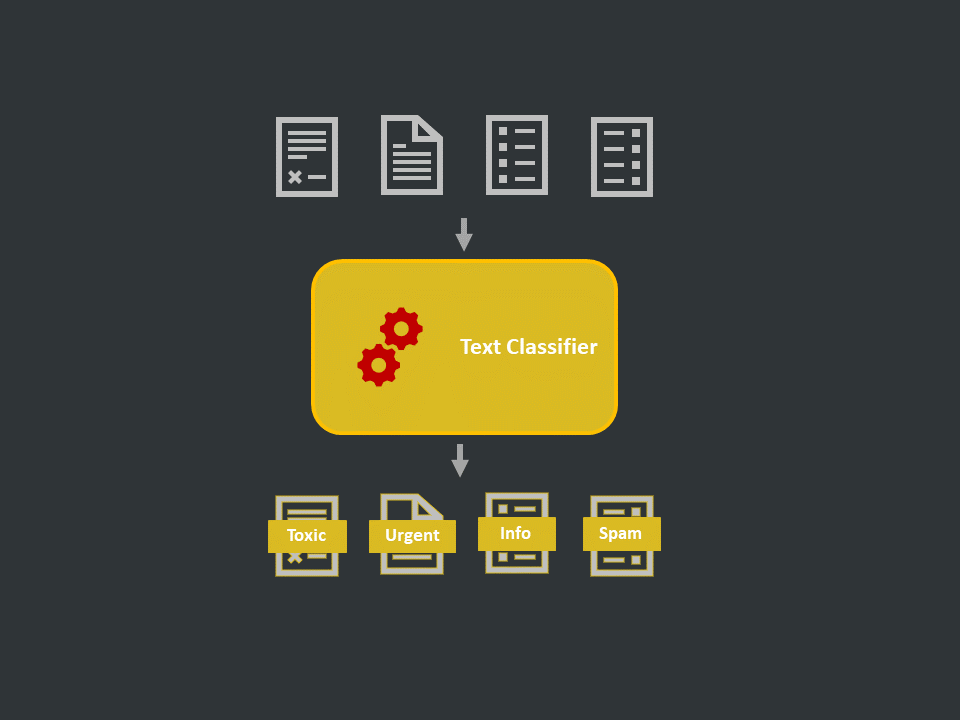
Introduction
- Definition: Text classification is a supervised learning method for learning and predicting the category or the class of a document given its text content. The state-of-the-art methods are based on neural networks of different architectures as well as pre-trained language models or word embeddings.
- Applications: Spam classification, sentiment analysis, email classification, service ticket classification, question and comment classification
- Scope: Muticlass and Multilabel classification
- Tools: TorchText, Spacy, NLTK, FastText, HuggingFace, pyss3
Models
FastText
Bag of Tricks for Efficient Text Classification. arXiv, 2016.
fastText is an open-source library, developed by the Facebook AI Research lab. Its main focus is on achieving scalable solutions for the tasks of text classification and representation while processing large datasets quickly and accurately.
XLNet
XLNet: Generalized Autoregressive Pretraining for Language Understanding. arXiv, 2019.
BERT
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv, 2018.
TextCNN
What Does a TextCNN Learn?. arXiv, 2018.
Embedding
Feature extraction using either any pre-trained embedding models (e.g. Glove, FastText embedding) or custom-trained embedding model (e.g. using Doc2Vec) and then training an ML classifier (e.g. SVM, Logistic regression) on these extracted features.
Bag-of-words
Feature extraction using methods (CountVectorizer, TF-IDF) and then training an ML classifier (e.g. SVM, Logistic regression) on these extracted features.
Process flow
Step 1: Collect text data
Collect via surveys, scrap from the internet or use public datasets
Step 2: Create Labels
In-house labeling or via outsourcing e.g. amazon mechanical turk
Step 3: Data Acquisition
Setup the database connection and fetch the data into python environment
Step 4: Data Exploration
Explore the data, validate it and create preprocessing strategy
Step 5: Data Preparation
Clean the data and make it ready for modeling
Step 6: Model Building
Create the model architecture in python and perform a sanity check
Step 7: Model Training
Start the training process and track the progress and experiments
Step 8: Model Validation
Validate the final set of models and select/assemble the final model
Step 9: UAT Testing
Wrap the model inference engine in API for client testing
Step 10: Deployment
Deploy the model on cloud or edge as per the requirement
Step 11: Documentation
Prepare the documentation and transfer all assets to the client
Use Cases
Email Classification
The objective is to build an email classifier, trained on 700K emails and 300+ categories. Preprocessing pipeline to handle HTML and template-based content. Ensemble of FastText and BERT classifier. Check out this notion.
User Sentiment towards Vaccine
Based on the tweets of the users, and manually annotated labels (label 0 means against vaccines and label 1 means in-favor of vaccine), build a binary text classifier. 1D-CNN was trained on the training dataset. Check out this notion
ServiceNow IT Ticket Classification
Based on the short description, along with a long description if available for that particular ticket, identify the subject of the incident ticket in order to automatically classify it into a set of pre-defined categories. e.g. If custom wrote "Oracle connection giving error", this ticket type should be labeled as "Database". Check out this notion.
Toxic Comment Classification
Check out this notion.
Pre-trained Transformer Experiments
Experiment with different types of text classification models that are available in the HuggingFace Transformer library. Wrapped experiment based inference as a streamlit app.
Long Docs Classification
Check out this colab.
BERT Sentiment Classification
Scrap App reviews data from Android playstore. Fine-tune a BERT model to classify the review as positive, neutral or negative. And then deploy the model as an API using FastAPI. Check out this notion.
Libraries
- pySS3
- FastText
- TextBrewer
- HuggingFace
- QNLP
- RMDL
- Spacy
Common applications
- Sentiment analysis.
- Hate speech detection.
- Document indexing in digital libraries.
- Forum data: Find out how people feel about various products and features.
- Restaurant and movie reviews: What are people raving about? What do people hate?
- Social media: What is the sentiment about a hashtag, e.g. for a company, politician, etc?
- Call center transcripts: Are callers praising or complaining about particular topics?
- General-purpose categorization in medical, academic, legal, and many other domains.
Links
- Text Classification - PyTorch Official
- Building a News Classifier ML App with Streamlit and Python
- https://github.com/brightmart/text_classification
- IMDB Sentiment. Tensorflow.
- XLNet Fine-tuning. Toxic Comment Multilabel.
- XLNet Fine-tuning. CoLA.
- Classification Demo Notebooks
- Microsoft NLP Recipes
- Report on Text Classification using CNN, RNN & HAN
- Implementing a CNN for Text Classification in TensorFlow
- prakashpandey9/Text-Classification-Pytorch
- Google Colaboratory
- Classify text with BERT | TensorFlow Core
- Deep Learning Based Text Classification: A Comprehensive Review
- https://stackabuse.com/text-classification-with-bert-tokenizer-and-tf-2-0-in-python/
- https://colab.research.google.com/github/tensorflow/hub/blob/master/examples/colab/tf2_text_classification.ipynb
- https://blog.valohai.com/machine-learning-pipeline-classifying-reddit-posts
- https://www.kdnuggets.com/2018/03/simple-text-classifier-google-colaboratory.html
- https://github.com/AbeerAbuZayed/Quora-Insincere-Questions-Classification
- Document Classification: 7 pragmatic approaches for small datasets | Neptune's Blog
- Multi-label Text Classification using BERT - The Mighty Transformer
- https://github.com/fchollet/deep-learning-with-python-notebooks/blob/master/3.6-classifying-newswires.ipynb
- XLNet Fine-Tuning Tutorial with PyTorch
- Text Classification with XLNet in Action
- AchintyaX/XLNet_Classification_tuning
- https://github.com/Dkreitzer/Text_ML_Classification_UMN
- https://colab.research.google.com/github/markdaoust/models/blob/basic-text-classification/samples/core/get_started/basic_text_classification.ipynb
- https://towardsdatascience.com/how-to-do-text-binary-classification-with-bert-f1348a25d905
- https://colab.research.google.com/github/tensorflow/hub/blob/master/docs/tutorials/text_classification_with_tf_hub.ipynb
- https://github.com/thomas-chauvet/kaggle_toxic_comment_classification
- https://github.com/scionoftech/TextClassification-Vectorization-DL
- https://github.com/netik1020/Concise-iPython-Notebooks-for-Deep-learning/blob/master/Text_Classification/classification_imdb.ipynb
- https://github.com/getmrinal/ML-Notebook/tree/master/17. textClassificationProject
- https://github.com/mpuig/textclassification
- https://github.com/netik1020/Concise-iPython-Notebooks-for-Deep-learning/blob/master/Text_Classification/self_Attn_on_seperate_fets_of_2embds.ipynb
- https://github.com/fchollet/deep-learning-with-python-notebooks/blob/master/3.5-classifying-movie-reviews.ipynb
- sgrvinod/a-PyTorch-Tutorial-to-Text-Classification