Named Entity Recognition
Introduction
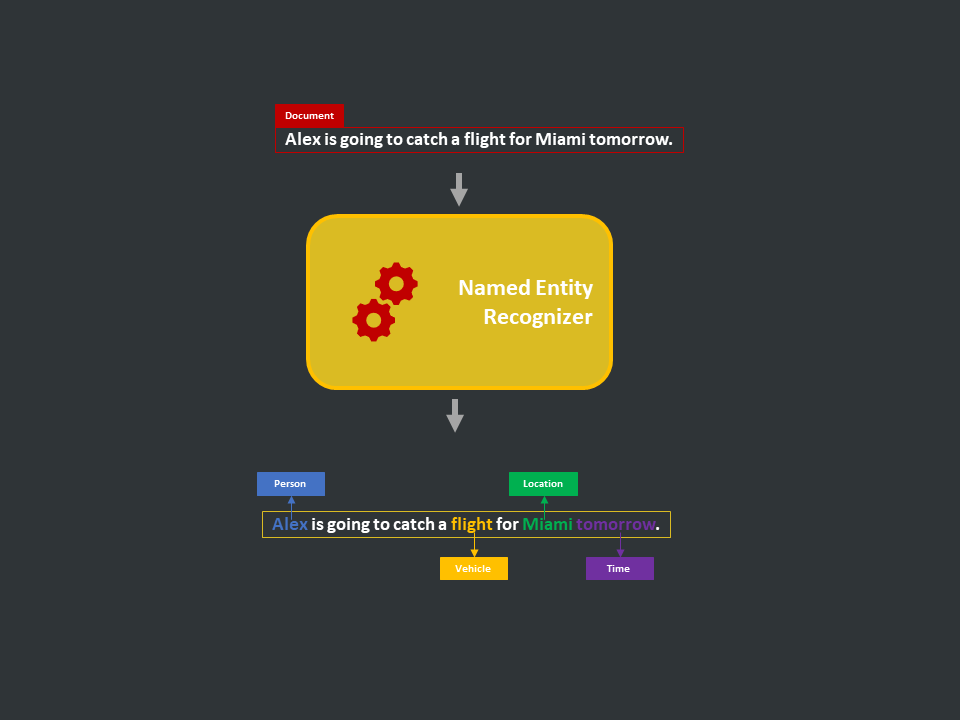
- Definition: NER models classify each word/phrase in the document into a pre-defined category. In other words, these models identify named entities (classes/labels) in the given text document
- Applications: Opinion mining, Affinity towards brands
- Scope: No scope decided yet
- Tools: Doccano, Flair, Spacy, HuggingFace Transformer Library
Models
Flair-NER
Pooled Contextualized Embeddings for Named Entity Recognition. ACL, 2019.
Contextual string embeddings are a recent type of contextualized word embedding that were shown to yield state-of-the-art results when utilized in a range of sequence labeling tasks. This model achieves an F1 score of 93.2 on the CoNLL-03 dataset.
Spacy-NER
Incremental parsing with bloom embeddings and residual CNNs.
spaCy v2.0's Named Entity Recognition system features a sophisticated word embedding strategy using subword features and "Bloom" embeddings, a deep convolutional neural network with residual connections, and a novel transition-based approach to named entity parsing.
Transformer-NER
Fine-tuning of transformer based models like BERT, Roberta and Electra.
Process flow
Step 1: Collect Text Data
Fetch the raw text dataset into a directory.
Step 2: Create Labels
Use open-source tools like Doccano or paid tools like Prodigy to annotate the entities.
Step 3: Model Training & Validation
Train the NER model and validate it.
Step 4: UAT Testing
Wrap the model inference engine in API for client testing. We will receive a text document from the user, encode it with our text encoder, find TopK similar vectors using Indexing object, and retrieve the text documents (and metadata) using dictionaries. We send these documents (and metadata) back to the user.
Step 5: Deployment
Deploy the model on cloud or edge as per the requirement.
Step 6: Documentation
Prepare the documentation and transfer all assets to the client.
Use Cases
Name and Address Parsing
Parse names (person [first, middle and last name], household or corporation) and address (street, city, state, country, zip) from the given text. We used Doccano for annotation and trained a Flair NER model on GPU. Check out this notion.
NER Methods Experiment
Data is extracted from GMB(Groningen Meaning Bank) corpus and annotated using BIO scheme. 10 different NER models were trained and compared on this dataset. Frequency based tagging model was taken as the baseline. Classification, CRF, LSTM, LSTM-CRF, Char-LSTM, Residual-LSTM-ELMo, BERT tagger, Spacy tagger and an interpretable tagger with keras and LIME were trained. Checkout this notion.